In-Depth
Best Practices for Setting Up Resilient Databases for Scalability, High Availability and Disaster Recovery
For IT professionals dealing with databases, a few processes can ensure flexibility and stretch the limits of uptime.
When it comes to mission-critical systems and databases, we all know that we need to plan for disaster. It's not the most exciting work; there's often little reward even when it's well done, and the only upside is when a crisis is averted. Working the help desk might look more glamorous.
For any new or critical system, IT pros should approach scalability, high availability (HA) and disaster recovery (DR) in a unified, holistic manner. Unfortunately, for most systems, organizations tend to approach them separately, or not at all.
DR, HA and scalability all factor into our database resilience requirements. Based on a financial risk assessment, the goal for each system is to work out how resilient the database should be to meet our needs. Whether the system is already operational, or just in the design phase, each system should be reviewed and assessed for its risks and goals for DR, HA and scalability as they relate to the business.
Risk and Goals
While it's easy to declare that your organization needs a strategy to manage databases for DR, HA and scalability risk, the more difficult and far more important question that you really need to ask is: What is the real risk if the database goes offline?
As a business, establish what the stated business goals are for the user and customer community. Everyone wants to declare 24x7 goals, but is that really in budget? For many operational systems, business-day seven-to-seven -- or even just nine-to-five -- uptime may be sufficient. If you're an Internet-driven company like Google Inc. or Yahoo! Inc., 24x7 is a must. If not, when an operational system goes offline for 30 minutes, it may only be a hassle, not devastating. An honest assessment of the downtime risk is critical. Costs can increase exponentially as the requirements for DR/HA and scalability increase, as shown in Figure 1.
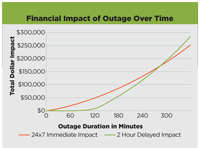
[Click on image for larger view.] |
| Figure 1. The negative financial impact of a system outage compounds itself over time, so disaster recovery (DR), high availability (HA) and scalability are critical. But increasing the requirements for DR/HA/scalability can lead to exponential increases in costs.
|
It's important to identify the potential impact due to lost revenue, outage costs, SLA payouts and any long-term effects on the organization's reputation. It's not easy and it may not be perfect, but it should be done for every system. With a clear understanding of the financial impact to the business due to a database outage, you can focus on your priorities.
All for One, or One at a Time
With the release of SQL Server 2008, Microsoft increased its emphasis on HA with the introduction of the "Always On Technologies" program for SQL Server. The program highlights the various native software features included with SQL Server 2008, along with a list of hardware vendors that meet specified storage requirements. Microsoft has continued to make improvements to SQL Server over the years to enhance resilience.
Although it's often last on the list of database issues to address, scalability needs to be your first priority. Can you scale with a centralized database, or do you need to consider a tightly integrated, geographically disbursed approach from the start? Is there a design that unifies scalability, DR and HA into a single database-resilient strategy? If the answer is yes, the solution most likely will rely on one of the unified, shared-nothing approaches available. The most popular of these are peer-to-peer (P2P) replication and the xkoto Inc. GridScale appliance.
Replication was introduced in 1995 as part of SQL Server 6.0, and over the past 16 years it has continued to improve. From the beginning, replication was intended to address volume-driven outages, both locally and geographically disbursed. Typically, tables supporting high user loads can be published to multiple, geographically disbursed locations for read-only access. Changes, which occur less frequently, can be managed in a centrally located publishing database. But with this publish-out approach, you can only solve part of your scalability issues. All database data changes are still centralized. And DR and HA issues for the centralized publisher still need to be addressed.
Replication does have an approach with the ability to address not only your scalability issues, but also DR and HA. Using P2P replication, you can set up multiple, geographically disbursed databases that provide fully redundant database sites. Complexity is the primary deterrent. While most DR and HA approaches are at the database or server level, replication is at the table level of granularity. This makes perfect sense when you're only publishing selected high-use tables to address volume-outage issues. Unfortunately, using P2P replication for a complete DR/HA and scalability solution is far more complicated. Still, for some applications it could prove to be the ideal solution.
Scaling out Web servers using load balancers has become a relatively routine task. But using a load-balancing solution for databases? The database just begs to be a centralized solution. Even the highly regarded Oracle Real Application Cluster (RAC) design still requires a centralized database hidden behind all those RAC nodes.
But all this changed when xkoto released the GridScale appliance for DB2 and then for SQL Server several years ago. GridScale is effectively a combination load balancer and P2P replication appliance that sits between the application and the database. Database reads (selects) are diverted to the database server reported to have the least load. On the other hand, database change requests (insert/update/delete) are coordinated and managed across all the database servers in the union. It's a parallel configuration providing the potential for a highly scalable, geographically disbursed, fault-tolerant system. Each independent system provides both HA and DR for the others. And, unlike replication, it's managed at the database level.
Database Virtualization
Virtualizing database servers may be one of the last holdouts, but as virtualization continually improves its HA and fault-tolerant offerings, the benefits of database virtualization will slowly outweigh any potential obstacles. Configured on a blade server set up with a high-speed SAN connection, the virtual database server can be allocated with all server resources. If and when a server needs more computing power, it can simply be migrated to an upgraded virtual server. Downtime is minimized while providing scale-up potential. If the virtual database server is configured with database mirroring, we've gained HA. DR is still an issue, but log shipping may be sufficient.
While Microsoft Hyper-V and products from VMware Inc. take most of the mindshare for server virtualization, HP PolyServe offers a unique approach to server virtualization. PolyServe uses a proprietary "Shared Data" approach that utilizes aspects of clustering and virtualization to deliver a capable HA and consolidation option for managing SQL Server. While the primary market focus of PolyServe was originally intended for server consolidation, its design supports HA and, to some extent, scalability. As with virtualization, DR will still need to be addressed separately.
Clustering and Database Mirroring
In a perfect world, you could use clustering to handle both HA and DR for your SQL Server databases. Your clustered environment could be configured to support distributed partitioned views to handle your scalability requirements. Windows Server 2008 has made advances in supporting multi-site clustering, even removing the "same subnet" restriction. Unfortunately, clustered SQL Server 2008 still has the same subnet restriction, forcing configurations to fall back on a VLAN approach for a geographically disbursed clustered database. If you have the right MCSEs on your team, a multi-site clustered environment could be the ideal solution for supporting your database DR/HA and scalability needs.
With the addition of database mirroring in SQL Server 2005, HA became extremely accessible. Mirroring is easy to implement and administer, and the additional cost in most cases is nominal. If you have multiple databases, you can gain a nominal amount of scalability by configuring the databases where half are active on the first server with the other half active on the second server. It's not perfect, but it's effective and useful. Based on experience, the mirroring process adds a negligible 1 percent to 2 percent load on the server -- which is well worth the benefit gained.
The mirroring technology in SQL Server has two very different core approaches: high safety and high performance. High safety provides the synchronized mirroring approach that you expect when you think of database mirroring. On a LAN, it provides the HA you're looking for, but with no provision for either DR or scalability. Technically, you can deploy the high-safety mode across a WAN, but if you're using a heartbeat monitor for the mirror, you have to make some uneasy decisions as to where the monitor will reside and how any WAN outages will affect your mirroring configuration.
The second approach is the asynchronous high-performance mode. Here, asynchronous is the key. The active server continually passes transactions to the passive server, but there's no attempt to wait for confirmation back from the passive mirror. The best use for high performance, as confirmed in the SQL Server Books Online (BOL), is for DR situations. Realistically, it's rather more like log shipping on steroids, where instead of shipping logs, it ships at the transaction level. Unfortunately, you have to choose between high safety and high performance. If you could combine a LAN-based high-safety mirroring setup with a high-performance mirror over a WAN, you'd have a sound and easy-to-implement HA and DR configuration -- if it was supported. Perhaps this should be added to the wish list for SQL Server.
That still leaves scalability wide open and dependent on scaling up. If you're using high-safety mode failover, the database moves from one server to the other, allowing for a relatively easy path for swapping in bigger hardware. And for DR, you can fall back on log shipping.
Another option for mirroring is the Neverfail Ltd. product line. While SQL Server mirroring operates at the database level, Neverfail promotes mirroring at the server level. Mirroring can be either local or over a WAN for DR coverage. Because databases are transactional, due diligence is critical to ensure server-based mirroring will capture all the transactions in the event of a failover.
Before mirroring was introduced, log shipping was just about the only tool available to support HA and DR. As the name implies, the process ships the database transaction logs to one or more alternate (secondary) database servers running in standby mode.
Shipping the transaction logs to both a local standby server and a remote standby server provides a fairly solid DR and near-HA solution. Within a matter of minutes, one of the standby database servers could be recovered and online with only minimal transaction data loss. A key determinant of the extent of data loss is the frequency of transaction log backups, and the speed with which they're transmitted over the network to the standby servers. But, as with mirroring, scalability is typically covered with a scale-up approach.
Database Backup
With all of the advancements in database resiliency, the most common approach used for both HA and DR is the off-site full backup. Following a sound financial-impact calculation, if the databases are offline for a few days the implication is that the company will incur only a minor financial loss as a result of the outage.
With only off-site backups for DR, when an event occurs, the off-site data is already a few days old. The tapes are nearly a day old when they're sent to storage. And it may take a day or more just to retrieve them and fully restore the systems. Can your business afford to lose two days of lost transactions?
Aligning with Goals
Overall, when assessing the financial impact of a system outage -- along with all the potential options available -- it's clear that no one ideal solution exists. There are multiple tools and approaches to manage database resilience, and each has its own pros and cons that must be matched to the overall business goals and requirements. It's not a simple, straightforward decision, but there are some very useful and workable options.
Organizations that choose to manage databases on-premises rather than taking the cloud option must do their due diligence in choosing the best option for ensuring database resiliency. The key is for the method employed not only to meet requirements for DR/HA/scalability but also to align with the organization's financial and uptime goals. Not every DR/HA/scalability plan needs to provide 24x7 uptime, but each one must be set up to meet a particular organization's specific needs.