Joey on SQL Server
Scaling Databases for Large Multi-Tenant Applications
Understanding your customer base and planning early are essential steps when designing a scalable, multi-tenant database architecture that balances cost, performance and isolation.
- By Joey D'Antoni
- 09/16/2025
Building and maintaining multi-tenant database applications is one of the more challenging aspects of being a developer, administrator or analyst. Until the debut of AI systems, with their power-hungry GPUs, database workloads represented the most expensive workloads because of their demands on memory, CPU and storage performance to work effectively.
In this month's column, I wanted to cover some of the general thought processes of how and what to build in terms of database architecture for large scale applications. We will primarily focus on databases here -- not that application tiers are trivial -- but more importantly, they are generally stateless, meaning they do not retain information (stored in the database), so it is easier to share them between tenants. Also, no one tends to care about 2 CPU/8 GB VMs until you have hundreds of them.
Before we begin, let's define tenancy. It's an overloaded term in the information technology industry. A tenant refers to a group of users or an organization that shares common access with specific privileges to the software instance. When we speak of multi-tenant applications, I tend to think of software-as-a-service applications like Salesforce or Office 365, in which many organizations share common compute infrastructure.
While sharing that compute infrastructure, every essential and hard-to-do part is providing firm boundaries to ensure all data remains within the virtual walls of each tenant, while maintaining performance and achieving cost of goods sold (COGS) targets. If Company A can see Company B's emails in their Office 365 account, Microsoft suddenly has significant problems. You need to keep that in mind when you are designing your own architecture for your own multi-tenant apps. There are two extremes as to how to model this: give each of your customers their own environment (the strongest isolation and the highest cost), and the other extreme is to pile all customer data into a single database, or even a single table (the lowest isolation, the lowest cost (until you get fined).
As I was in the process of writing this column, two recruiters reached out to me about the same contracting opportunity, where the client had an 18 TB table in an Azure Hyperscale SQL DB. While I think Hyperscale is a great platform, I commented on social media that "an 18 TB table in an online transaction processing (OLTP) database means you did something terribly wrong." What I meant by that is that there are better design patterns for transactional systems, and if your main table gets that big, you probably didn't follow those design patterns, or you did something especially egregious, such as storing pictures or videos in an operational database. Let's discuss the best approach to designing databases for large-scale, multi-tenant applications.
The first step is to understand who you are customers are going to be:
- Are your customers going to be consumers (think Facebook)? If this is the case, you need to design for millions and possibly billions of users. The tradeoff for consumer data is less isolation for lower COGs.
- Are your customers going to be businesses (think QuickBooks here)? This pattern can still mean a large, distinct number of customers -- so if this is the case, you need to ask some more questions. The design pattern for business is higher levels of isolation and higher COGs, because presumably, you will have more revenue than from consumers.
- If your customers are businesses, you want to understand the total available market for your application. There are business-to-business applications that are wildly profitable, serving single-digit customers (admittedly, these customers are usually large governments). In contrast, a service like QuickBooks is closer to a consumer app in terms of the number of users.
Effectively, we are trying to understand the number of distinct customers the application will have and then choose a database design pattern accordingly. I want to emphasize how crucial it is to undertake this planning in the early stages of application design. None of these solutions is difficult to implement while building a new application; however, changing the data access layer of a running app is akin to changing the engines on an airplane while it's flying.
The way nearly all large global-scale applications utilize partitioning techniques is to spread data across databases effectively. This concept, called database sharding, is similar to table partitioning in Oracle or SQL Server; however, working across databases allows you to scale far beyond the capacity of a single server.
The Tools and Framework
Sharding is a data management technique that effectively partitions data across multiple databases. At its center, you need something that I like to call a command and control database. Still, I've also seen it called a shard-map manager or a router database. This database contains the metadata around the shards and your environment, and routes application calls to the appropriate shard or database.
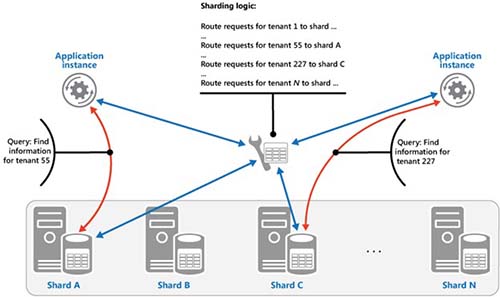 [Click on image for larger view.]
Figure 1. An example of a sharded database architecture with routing.
[Click on image for larger view.]
Figure 1. An example of a sharded database architecture with routing.
There are several different ways you can shard your databases. Based on lookup, like shown above, range (customers 1-10 on Shard A, 1-20 on Shard B, etc.) or a hash strategy. If you understand table partitioning, you probably understand these concepts. The big difference here is the data is spread across all of those databases. As I explained above, this is really something you want to design into your application from the beginning. Another aspect you want to plan for is shard management. If one of your shards gets really hot, you need to think about how to either give it more resources, or split it half.
If you are working on the Microsoft stack, I'm going to give a shout out to elastic database tools. This .NET library gives you all the tools like shard-map management, the ability to do data-dependent routing, and doing multi-shard queries as needed. Additionally, consider the ability to add and remove shards to match shifting demands. Figure 2 shows an example architecture of all of these tools working together.
 [Click on image for larger view.]
Figure 2. A more complex application stack built around sharded databases.
[Click on image for larger view.]
Figure 2. A more complex application stack built around sharded databases.
Some other tooling you need to think about in planning, are how to execute schema changes across your partitions. Database DevOps is a mature practice, but rolling out changes across is fleet of databases requires careful forethought and operations. You also need to think about how to report and retrieve both operational and business data from your fleet of databases. You also, want to have a data archiving strategy -- a good approach here is to use object storage like Azure Blob or Amazon S3 which offer effectively limitless, cost-effective storage.
Not everyone needs to build a large scale, complex sharded database structure. In fact, most applications can run in a single database -- sometimes even in a container. However, it's helpful to understand the patterns that large scale applications use, so that when you are presented with a more challenging set of requirements, you can build a system to meet those requirements. This post is just a start to your studies though -- there's other concepts like global distribution, availability, and multiple cluster design to think of.
About the Author
Joseph D'Antoni is an Architect and SQL Server MVP with over two decades of experience working in both Fortune 500 and smaller firms. He holds a BS in Computer Information Systems from Louisiana Tech University and an MBA from North Carolina State University. He is a Microsoft Data Platform MVP and VMware vExpert. He is a frequent speaker at PASS Summit, Ignite, Code Camps, and SQL Saturday events around the world.