Joey on SQL Server
How Microsoft Is Building the Biggest Cloud Database
Microsoft broke new ground in scalability when it launched Azure SQL Database Hyperscale. Here's what it took to make Microsoft's hyperscale vision work with the existing Azure infrastructure.
- By Joey D'Antoni
- 07/03/2019
When Microsoft introduced SQL Azure (initially called SQL Data Services) in 2008, database size was limited to either 1GB or 5GB, depending on your service tier.
Even back then, that was an extremely low limit for the average data volumes of the time. As the service evolved -- and occasionally changed names -- the Azure SQL Database service emerged to give users support for storing up to 4TB in a single database.
But while 4TB is a lot of data for most folks, there are many workloads that require much more data than that. In order to meet the needs of those large data sets, Microsoft introduced Azure SQL Database Hyperscale, previously code-named "Socrates." Azure SQL Database Hyperscale became generally available in May at the Microsoft Build conference.
Making changes to underlying cloud infrastructure is challenging. Microsoft operates Azure in over 54 regions worldwide, with each region consisting of one or (in most cases) more datacenters. Trying to get new hardware deployed across the world is challenging for any organization, so you can imagine the difficulty Microsoft faces with managing Azure. What this means is that product teams need to introduce features that scale, but that scale horizontally, rather than just buying a bigger box.
The current Azure SQL Database limit of 4TB is based on the maximum size of the local solid-state drive (SSD) in a given physical server. The aim of Azure SQL Database Hyperscale is to create a service that supports databases of up to 100TB and beyond. To meet those goals, Microsoft had to take a ground-breaking approach to scaling out the underlying infrastructure.
If you have any experience working with relational databases, you probably recognize that designing a scale-out database solution is an interesting proposition. The common design tactic to achieve transactional consistency, one of the fundamental principles of the relational model, has been a single log file that records all transactions, better-known as the transaction log.
Another trial that Microsoft faced in building this model is the lack of specialized high-performance storage in its cloud platform. Azure Storage is all network-attached and uses an object-based design, which means it has slightly higher latencies than specialized storage area networks (SANs). That, combined with the limits of the overall size and hardware available in cloud-based virtual machines, meant a novel approach had to be taken.
In the existing Azure SQL Database architecture, Microsoft has leveraged technology similar to Always On availability groups to provide both high availability and durability. This required four copies of the data, which were kept in sync via log records being shipped to all replicas.
While this was a robust solution, it had a couple of key limitations. The size of a database could not grow beyond the storage capacity of a single machine, and the performance costs of large storage operations -- such as backup and restore or seeding a new availability replica -- grow linearly with the size of the database. These reasons are why the current limit of 4TB exists.
To overcome all of these obstacles, Microsoft made a few architectural decisions and feature enhancements. First, let's focus on the SQL Server features. There are several core improvements to SQL Server that are driving Azure SQL Database Hyperscale, but were probably missed or unused by many on-premises DBAs.
The first is snapshot-based backups: SQL Server 2012 introduced the ability to store data files in Azure Storage as http endpoints, and later advances in Azure Storage combined with code enhancements allowed for constant backup with very fast restore times, even at hundreds of terabytes.
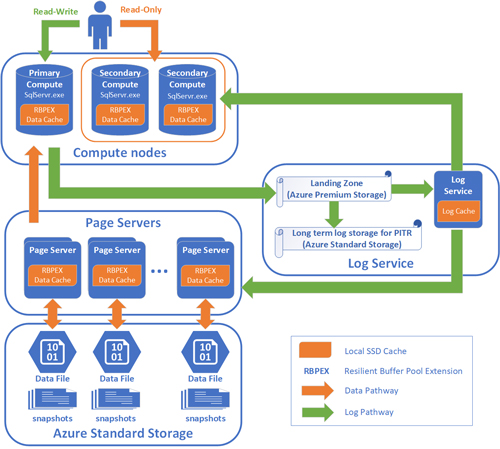 [Click on image for larger view.] Figure 1: Hyperscale architecture. (Source: Microsoft document)
[Click on image for larger view.] Figure 1: Hyperscale architecture. (Source: Microsoft document)
Another feature used here that debuted to minimal fanfare on-premises is buffer pool extensions (BPE), or the ability to extend the buffer pool of SQL Server onto local SSD to simulate having more RAM. In Azure SQL Database Hyperscale, Microsoft further improved this feature with the use of Hekaton, its in-memory, latch-free database structure, to make the data written there recoverable in the event of failure. BPE, which is now called RBPEX for "resilient buffer pool extension," ultimately allows the scaling-out of data via the use of page servers.
Page servers are a key element of this scale-out architecture. Each page server stores a subset of the data in your database, which is somewhere between 128GB and 1TB. Page servers are kept up-to-date by transaction log records being played back to them.
Another enhancement here is the Accelerated Database Recovery feature in SQL Server 2019, which makes the undo phase of recovery much faster. Each server uses an SSD-based cache using RBPEX on local SSD. Durability of the Azure data pages is provided by the underlying Azure Storage infrastructure.
The database engine lives on what are called compute nodes. These compute nodes have SSD-based caches that are designed to reduce the number of trips to the page servers to retrieve data. Just like in an on-premises SQL Server implementation, only one compute node can process reads and writes. However, there are secondary nodes that provide failover support and scale-out of read workloads.
The transaction log is broken out into its own service. As writes come into the primary data node, the log service persists them to Azure Premium Storage SSDs and persists those write operations into a cache, which in turn forwards the relevant log records to both the compute nodes and the page server nodes to keep them up-to-date. Finally, the log records are stored in Azure Storage for long-term retention, eliminating the need for the DBA to truncate the log.
Azure SQL Database Hyperscale offers an interesting approach to scale-out data service. You will note that there is no on-premises offering of this feature; the public cloud offers the nearly infinite scale and consistent deployment platform that is required to have the service work as expected.
Given the way Microsoft has developed its data platform, I would not be surprised to see hyperscale makes its way into other service offerings like PostgreSQL or MySQL, or even the Azure SQL Database Managed Instance offering.
About the Author
Joseph D'Antoni is an Architect and SQL Server MVP with over two decades of experience working in both Fortune 500 and smaller firms. He holds a BS in Computer Information Systems from Louisiana Tech University and an MBA from North Carolina State University. He is a Microsoft Data Platform MVP and VMware vExpert. He is a frequent speaker at PASS Summit, Ignite, Code Camps, and SQL Saturday events around the world.