Joey on SQL Server
Back-to-Back Azure Portal Outages Expose Front Door Weaknesses
Two cascading disruptions tied to Azure Front Door updates left global users unable to access the Azure Portal, offering a case study in how cloud complexity and outdated APIs can turn maintenance into widespread downtime.
- By Joey D'Antoni
- 10/17/2025
After speaking at the DataMinds Connect conference last week in Belgium on the current political ecosystem of the cloud, I was connecting through London Heathrow. I had a long layover and was working all morning. I tried to log in to the Azure Portal and received a message saying, "Your internet is not working."
This was curious since it was a Web page served by the Azure Portal. A quick search of Reddit and an MVP mailing list revealed that we were in the midst of an outage. The outage turned out to be related to Azure Front Door (AFD).
Let's examine what happened, how you could potentially protect against future outages and, finally, how Microsoft responded and handled the situation.
If you aren't a network engineer, you may not be familiar with Azure Front Door, which Microsoft defines as an advanced cloud Content Delivery Network (CDN), "designed to provide fast, reliable, and secure access to your applications' static and dynamic Web content globally." Front Door is more than that -- in addition to its CDN functionality, it provides global load balancing with over 118 point-of-presence locations to deliver pages more quickly to your users wherever they are. However, Front Door is way more than a simple CDN. In one example, I'm using Front Door to provide a custom URL for the Entra authentication page in my app. You can write complex rules to perform URL rewriting for an application.
Front Door is a widely used, complex set of networking services, used both inside and outside of Microsoft. The ubiquity of this service also means that when there are problems with Front Door, many services and companies become unhappy. When the outage happened last week, the health status portal was slow to update. Still, Microsoft quickly acknowledged the outage via email and social media. Note to cloud providers: maybe don't host your status pages in your own cloud services (I'm not just picking on Microsoft here, AWS has had the same issues frequently).
The Front Door Outage: What Happened?
I want to give Microsoft Azure's teams much credit here -- the preliminary postmortem was up
just a day after the incident. Microsoft was making some changes to the AFD control plane to update it to the latest version. During the upgrade process, Microsoft observed Front Door creating erroneous metadata, which led to failures. While fixing that problem and cleaning up the invalid metadata, a bug in the data plane was triggered, disrupting many edge sites in Europe and Africa, which is why I couldn't log in to the Azure portal.
You can think of this as a database update that caused an application to behave incorrectly if the update used the wrong target values. Front Door was able to recover from the edge sites being down by routing traffic to other sites; however, these locations became overloaded, leading to timeouts and increased latency. These explanations align with my experience in London, as I got into the Portal on about the fifth try.
A Bad Thursday: The Next Portal Outage
Not to go into too much detail on my travel, but by the time I landed in Philadelphia, there was another outage. The Azure Portal was once again unavailable. Was it Front Door again? Not exactly, but the two outages were related. During the earlier AFD outage, Portal automation-initiated scripts had some traffic to the Portal that bypassed AFD. However, the scripts accidentally removed a config value due to the use of an older, mismatched API version. The version of the API didn't have that value, so calls deleted the relevant data value. This deletion falsely caused AFD endpoints to report as unhealthy, and they stopped routing traffic. During the initial parts of this second outage, Microsoft reverted to the old routing of the Azure Portal through Front Door. However, the missing data value was still not updated, leaving some of the management portals inaccessible. About two hours later, Microsoft was able to mitigate the routing issue fully.
The second outage goes to show the importance of testing your failover scenarios regularly. If Microsoft had tested these processes during a hot outage, it could have avoided the second outage caused by the API mismatch and subsequent data errors.
How To Make Front Door More Available
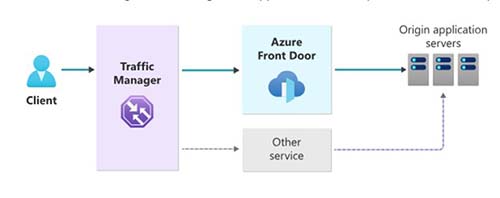
Another topic that I discussed with some architecture friends was how to design for failures in Front Door. By its nature, it's a global service, meaning you can't deploy a second one and failover to it. In the postmortem analysis, Microsoft made the following recommendation: "Consider implementing failover strategies with Azure Traffic Manager, to fail over from Azure Front Door to your origins."
 [Click on image for larger view.]
Figure 1. An image of that architecture is in the Well-Architected Framework documentation.
[Click on image for larger view.]
Figure 1. An image of that architecture is in the Well-Architected Framework documentation.
Microsoft leaves "Other service" unnamed there. Conceivably, you could go multi-cloud here; however, there are gaps in using some equivalent AWS WAN services compared to Azure. Cloudflare has a sufficient set of services that you could build a solution on their stack, use Azure Traffic Manager as DNS in front of that and, in the event of failure, switch over to it. How well this works depends on how tightly integrated your app is with Front Door. If you are doing global load balancing and CDN, Cloudflare will probably work fine. If you are doing a lot of advanced URL rewriting, while Cloudflare supports that, those rules may not map one to one, and you could have challenges with application functionality. If you're not familiar with URL rewriting it's a technique that allows you to route different requests to different services based on URL pattern. A really basic example would be to route traffic coming to redmondmag.com/video to a different backend server pool than redmondmag.com/articles.
I want to credit Microsoft for the very detailed incident report for both of these outages. Having that level of detail increases trust with customers. It allows architects to make better decisions on how to build more fault-tolerant systems. Even in the case of the second portal outage, we can learn from the mistakes that led to something of a cascading failure.
Lessons learned from this outage? Global load balancing solutions are incredibly complex pieces of software, and a minor problem can quickly lead to a cascading failure. It may or may not be worth it to build that redundancy into your system by adding another vendor. Always remember the importance of recovery time objective (RTO) and recovery point objective (RPO), and let those guide your decision, instead of "what's cool technically." Finally, test your failover process before something makes you have to.
About the Author
Joseph D'Antoni is an Architect and SQL Server MVP with over two decades of experience working in both Fortune 500 and smaller firms. He holds a BS in Computer Information Systems from Louisiana Tech University and an MBA from North Carolina State University. He is a Microsoft Data Platform MVP and VMware vExpert. He is a frequent speaker at PASS Summit, Ignite, Code Camps, and SQL Saturday events around the world.