Practical App
SQL Q&A: Users Questions Answered
Exploring distributed transactions, performance counters and SQL backups.
- By Paul S. Randal
- 04/01/2010
Q: We use a lot of distributed transactions and we are now investigating database mirroring to provide high availability to one of our critical databases. During our testing, we discovered that distributed transactions sometimes fail after we try to failover the mirror database. Can you explain what's going on?
A: This is actually a documented limitation of using distributed transactions. The limitation exists when using database mirroring or log shipping -- basically any technology where the Windows server name is different after a failover is performed.
When using Microsoft Distributed Transaction Coordinator (MSDTC) transactions, the local transaction coordinator has a resource ID that identifies the server on which it is running. When a mirroring failover occurs, the principal database becomes hosted on a different server (the mirroring partner), and so the resource ID of the transaction coordinator is different.
If a distributed transaction is active, the transaction coordinator on the mirroring partner tries to ascertain the status of the transaction and can't because it has the wrong resource ID; MSDTC doesn't recognize it as it wasn't originally involved in the distributed transaction. In that case, the distributed transaction must be terminated -- the behavior you are seeing.
A similar problem can occur with cross-database transactions (a simple transaction involving updates in more than one database). If one of the databases involved is mirrored and one isn't, it's possible for the cross-database transaction to commit in both databases. If a forced mirroring failover occurs (when the principal and mirror are not synchronized and a manual failover, allowing data loss, is performed), the committed transaction in the mirrored database may be lost -- breaking the integrity of the cross-database transaction.
This can occur if the mirrored database is not SYNCHRONIZED (see "Removing Index Fragmentation, Synchronizing vs. Synchronized, and More," TechNet Magazine, June, 2009, where I explain this more) and so the log records for the committed cross-database transaction have not yet been sent to the mirror. After the forced failover, the transaction does not exist in the new principal database and so the integrity of the cross-database transaction is broken.
Q: Recently I was monitoring some performance counters to figure out an issue with our database storage. While doing this I noticed something very strange: although there was nothing going on in the database, there was still write activity occurring to the database files. This happened for both the data and log files. I even made sure there were no connections to SQL Server, but it still continued. How can there be I/O activity when there are no connections?
A: SQL Server has a number of housekeeping operations that need to run; these are called background tasks. One or more of these is doing something on your system and causing I/Os. Here's a quick list of the possible culprits:
Ghost cleanup: A delete operation only marks records as deleted, as a performance optimization in case the operation is cancelled; it does not physically zero out the space. Once the delete operation has committed, something has to actually remove the deleted records from the database. This is done by the ghost cleanup task. You can read more about it on my blog, which also explains how to check if the ghost cleanup task is running (tinyurl.com/ycoft4o).
Auto-shrink: This is a task you can turn on to automatically remove empty space in a database. It works by moving pages from the end of the data files to the start, consolidating the free space at the end and then truncating the files. Although you can turn it on, you absolutely should not -- it causes index fragmentation problems (leading to poor performance) and uses a lot of resources. Usually you will have auto-grow enabled for a database, too, so you can get into a shrink-grow-shrink-grow cycle, which does a lot of work for no gain. You can check the status of all your databases with this query:
SELECT name, is_auto_shrink_on FROM sys.databases;
Deferred-drop: This task is responsible for doing the work required to drop or truncate tables and indexes (the index drop could be due to an index rebuild operation -- the new index is built and then the old one is dropped). For small tables and indexes, the de-allocation is done right away. For larger tables and indexes, the de-allocation is done in batches by a background task. This is to ensure that all necessary locks can be acquired without running out of memory. You can use the various deferred-drop performance counters to monitor this task, as described in Books Online.
Lazy writes: This task is responsible for removing old pages from the in-memory cache (called the buffer pool). When the server is under memory pressure, pages may have to be removed even though they have changes on them. In that case, the changed page must be written to disk before it can be removed from memory. You can use the "Lazy writes / sec" performance counter to monitor this task, as described in Books Online.
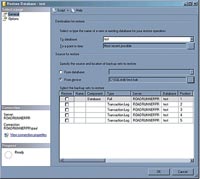
[Click on image for larger view.] |
| Figure 1. Using the SSMS Restore Database wizard to show multiple backups in a file. |
All of these have the potential to make changes to the database. They all use transactions to make the changes and whenever a transaction commits, the transaction log records generated by the transaction must be written to the log portion of the database on disk. Every so often as changes are being made to the database, a checkpoint must also occur to flush out changed data file pages to disk. You can read more about this in my article in the February 2009 issue of TechNet Magazine, "Understanding Logging and Recovery in SQL Server."
As you can see, just because there are no active connections to SQL Server, that doesn't necessarily mean that the process is quiescent -- it could be busy with one or more of the background tasks. If the I/O activity continues long after all of your database activity has completed, you may also want to check for scheduled jobs that may be running.
Q: I'm an involuntary DBA and I've been trying different things to come up to speed. The previous DBA set up jobs to take backups to a file but I can't figure out how to restore them. Is there any way to see what backups are in the file? And how can I restore them properly?
A: Although it is possible to append backups to the same file, most people put each backup in a separate file, with a meaningful name (and usually a date/timestamp combination). This can help to avoid the problem you're facing and make it easier to perform other tasks:
- Copying backups for safety is easy when each backup is in its own file. If all backups are in a single file, a copy of the latest backup can only be made by copying the entire backup file.
- Deleting old backups is not possible when all backups are in a single file.
- Accidentally overwriting existing backups isn't likely if each backup has a separately named file.
Unfortunately, that doesn't help your situation -- you already have a file with multiple backups inside it. However, there are two ways you can restore the backups: manually or using SQL Server Management Studio (SSMS).
To see what backups are in the file, you can use SSMS to create a New Backup Device that references the file. Once the reference is created, you can display the backup details for what's in this backup device. Or, you can use the RESTORE HEADERONLY command. Both of these will examine the backup device and provide one line of output describing each backup in the file. SSMS identifies backup types with a friendly name. Using the correct syntax, you will need to work out what type of backup each one is by using the information provided in the SQL Server Books Online entry for the command (see tinyurl.com/y9sgrkf for the SQL Server 2008 version) so that you can use the appropriate RESTORE command to restore the backup.
You will also need to work out which backup you want to restore. This is a little tricky because the output column name you need from RESTORE HEADERONLY does not match the option you must use to restore it. The backups in the file are numbered from 1, with 1 being the oldest, and the number can be found in the column called Position. To restore that backup, you must use the number in the WITH FILE= portion of a RESTORE command. Here's an example:
RESTORE DATABASE test FROM DISK =
'C:\SQLskills\test.bak' WITH FILE = 1, NORECOVERY;
RESTORE LOG test FROM DISK = 'C:\SQLskills\test.bak'
WITH FILE = 2, NORECOVERY;
And so on. You must start the restore sequence with a database backup and then restore zero or more differential database and/or transaction log backups. Further detail is beyond the scope of this column, but you can read more about restore sequences and the other RESTORE options you might need in my article "Recovering from Disasters Using Backups" (TechNet Magazine, November 2009).
Using SSMS, you specify the backup file in the Restore Database wizard and it will automatically show you all the backups in the file and allow you to select the ones you want. An example is shown in Figure 1.
Whichever option you choose, it's vital that you practice performing restores to another location before you have to do it for real when recovering from a disaster. One of my favorite principles is "You do not have a backup until you've done a successful restore."
Q: I have a pretty large database that I need to copy every few weeks to a development environment. My problem is that the database was recently grown in anticipation of more data coming in and now it's too big when I restore it in the development environment. How can I get it to be smaller when I restore it?
A: This is a fairly common question for which there is not, unfortunately, a good answer.
A backup of a database does not alter the database in any way -- it just reads all the used portions of the database and includes them in the backup, plus some of the transaction log (see my blog for an explanation of why and how much). A restore from a database backup just creates the files, writes out what was in the backup, and then runs recovery on the database. Basically, what you had in the database is what you get when you restore. There's no option to shrink a database on restore, address index fragmentation on restore, update statistics on restore, or any of the other operations people may want to perform.
So how to achieve what you want? You've got three options, depending on your exact scenario.
First, you could perform a shrink operation on the production database to reclaim the empty space. This would make the restored copy of the database the same as the production one, and without the wasted space, but at a potentially high cost. The production database would have to be grown again, and the shrink operation could be extremely expensive (in terms of CPU, I/O and transaction log) and cause index fragmentation. The index fragmentation would have to be addressed, taking more resources. This is not the option you want to use. (For a more in-depth explanation of the perils of using a data file shrink, see my blog.) You could consider only removing the free space at the end of the file (DBCC SHRINKFILE WITH TRUNCATEONLY) but this may not give you the reduction in size you need.
Second, if you only need to restore the production database once in development, you'll need to have enough space to restore the full-size database, and then shrink it to reclaim the space. After that you'll need to decide whether to address the fragmentation that was created by the shrink operation.
If you're going to be running queries for performance testing or for reporting, the fragmentation could cause a big drop in the performance of these queries. If you're not, you may not need to remove the fragmentation at all. To address the fragmentation, you can't rebuild the indexes (using the ALTER INDEX ... REBUILD command) as that requires extra space and will cause the database to grow again -- you'll need to reorganize the indexes (using the ALTER INDEX ... REORGANIZE command).
If you decide to remove fragmentation, be careful that you switch the database into the SIMPLE recovery model so the transaction log does not grow from all the transaction log records generated by the reorganizing. If you leave the database in the FULL recovery model, the log will continue to grow unless you take log backups -- something you probably want to avoid dealing with in a development copy of the database.
Finally, if you need to restore the production database multiple times in development, you're not going to want to repeat the steps in option 2 multiple times. In this case, it would be best to follow the steps in option 2 and then create a further backup of the shrunk (and maybe defragmented) database.
This second backup can then be used to perform multiple restores of the minimally sized production database.
To summarize, there is no easy way to move a production database that has a lot of free space to a development environment without that free space being required for the initial restore.
Special thanks to Kimberly L. Tripp of SQLskills.com for providing a technical review of this month's column.
Related Content
- Understanding SQL Server Backups
- Understanding Logging and Recovery in SQL Server
- SQL Server 2008: Advanced Troubleshooting with Extended Events
About the Author
Paul S. Randal is the managing director of SQLskills.com, a Microsoft regional director and a SQL Server MVP. He worked on the SQL Server Storage Engine team at Microsoft from 1999 to 2007. Randal wrote DBCC CHECKDB/repair for SQL Server 2005 and was responsible for the Core Storage Engine during SQL Server 2008 development. He is an expert on disaster recovery, high availability and database maintenance and is a regular presenter at conferences worldwide. He blogs at SQLskills.com/blogs/paul, and you can find him on Twitter at Twitter.com/PaulRandal.