Joey on SQL Server
Generative AI Impact on the Database
Once you're able to see through the "AI whitewashing," a strong case for generative AI in the database space can be made.
- By Joey D'Antoni
- 08/02/2023
In case you have been hibernating, all anyone has been talking about in technology in 2023 is AI. Driven by the introduction of large language models like ChatGPT and Llama, and their ease of accessibility, both businesspeople and technologists have been wildly speculating about the potential for these tools.
Depending on who you talk to, a) IT professionals should start learning to become plumbers; b) nothing will change; or c) admins and developers will have new tools in their arsenal to make them more productive.
This week, I did an online summit for Converge 360 discussing the current state of AI solutions in the Microsoft ecosystem. After that, I decided it would be interesting to do a column on the current state of AI in database systems. As with any hype cycle, one of the things you need to watch out for is what has been termed "AI washing." Techopedia defines this behavior in the following way:
"AI washing" involves claiming a product employs AI technology when it does not. If vendors continue to AI wash, "AI" will become just another buzzword -- which will decrease investor and public confidence in the technology.
We have seen this with other technology hype cycles in the past -- I can't tell you how many 20 GB "big data" systems I worked on in the early 2010s or how many vendor tools adopted "machine learning" several years later. With that in mind, I wanted to discuss a few things: the current state of database engines, an actual AI tool for writing SQL (GitHub Copilot) and potential future uses of AI technology to improve databases. The US National Institutes of Standards and Technology defines artificial intelligence as follows:
(1) A branch of computer science devoted to developing data processing systems that performs functions normally associated with human intelligence, such as reasoning, learning, and self-improvement.
(2) The capability of a device to perform functions that are normally associated with human intelligence such as reasoning, learning, and self-improvement.
While researching this article, I found a classic example of AI washing at the intersection of databases: "For example, Oracle's Autonomous Database uses AI to optimize SQL queries automatically."
While this is something I would consider to be precisely the marketing effort I described above, there is an element of truth here. Cost-based query optimizers use many of the principles of artificial intelligence to create more optimal execution plans. Cost-based optimizers incorporate several assumptions about relationships between data in a database and use column and indexing statistics to make better decisions.
There are a few other places you can see database engines using AI. Oracle, and Microsoft have automatic index creation in their cloud offerings. Microsoft presented this paper at the SIGMOD conference 2019, describing how this works in Azure SQL Database. In a nutshell, Microsoft bifurcates the query stream going into your database and experiments on a second shadow copy of your database, allowing it to test the indexes' efficacy before creating them on the primary replica.
Another example of a self-improvement feature in SQL Server is Automatic Tuning, which debuted in SQL Server 2017. This uses the query store functionality to force the last known good execution plan if CPU time increases beyond an internal threshold. While these features do not use large language models, they meet the NIST definition of AI, even if they use simple heuristics to make decisions.
Introducing Copilot for T-SQL
Microsoft made many announcements around AI at Build in May. One of the announcements was GitHub Copilot for Azure Data Studio, which aims to help developers write T-SQL queries more efficiently. You may know that SQL Server Management Studio and Azure Data Studio have long had Intellisense to make code suggesting for single words or phrases. The critical difference with Copilot is that it will offer entire lines of code. You can see a straightforward example in the GIF below.
 [Click on image for larger view.]
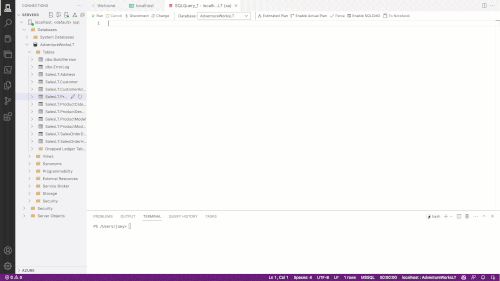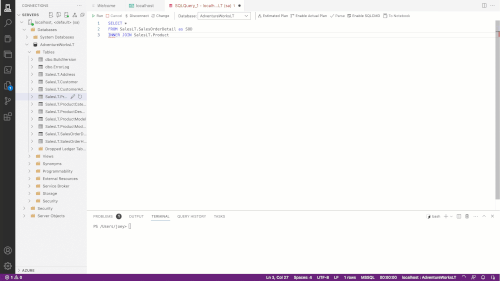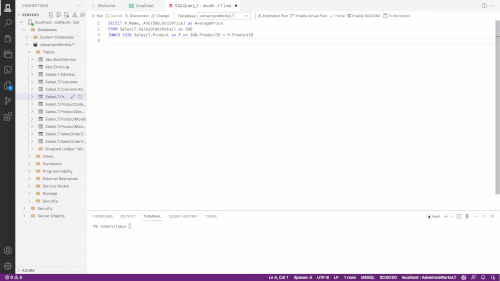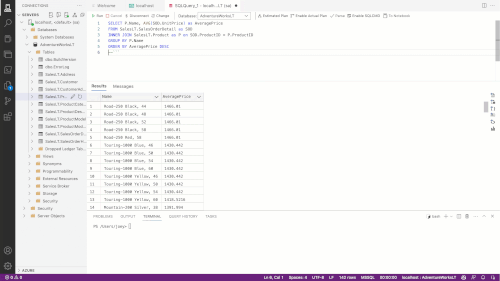
Figure 1.
[Click on image for larger view.]
Figure 1.
In the above example, I start by doing a SELECT * against a table and then try to join another table. Copilot helps me build out the JOIN syntax and helps me to use the aggregate function. Copilot can also use code comments to decide what code it wants to create, as shown in the below image:
 [Click on image for larger view.]
Figure 2.
[Click on image for larger view.]
Figure 2.
While that index is right for that query, I don't think Copilot makes any decisions based on other indexes that already exist on the table, so be careful with this to avoid over-indexing your tables. While over-indexing is a concern, developers not building indexes at all is a far more common problem, so I applaud this bit of intelligence.
The final test I used was to create a new table with just two columns and then instruct Copilot (via comment) that I wanted to use the T-SQL PIVOT to pivot the table. PIVOT is notorious for the complexity of its syntax. In an informal survey of Data Platform MVPs, I found they needed to use documentation to write a complete PIVOT. In this GIF, I added a comment that I wanted to pivot the data, and Copilot was smart enough to populate the syntax for me.
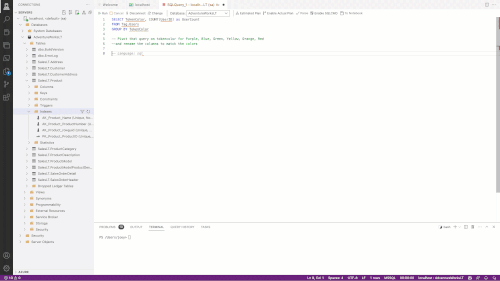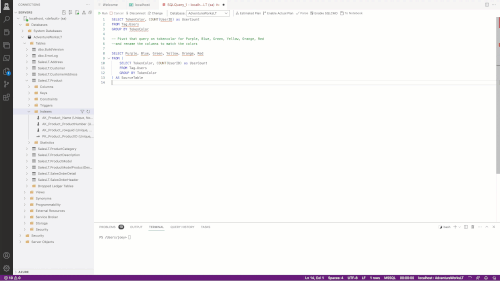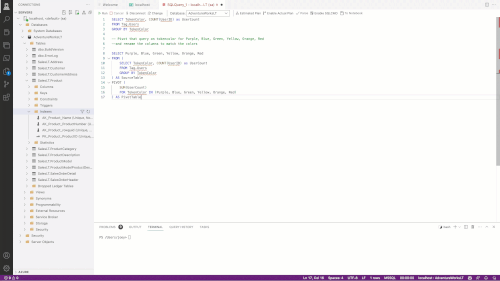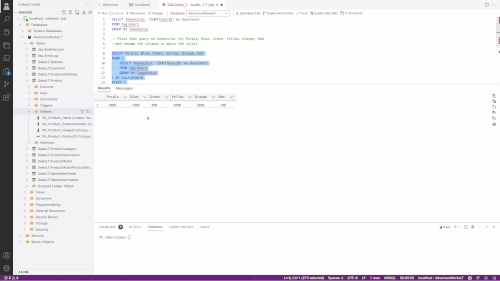 [Click on image for larger view.]
Figure 3.
[Click on image for larger view.]
Figure 3.
Does this mean T-SQL developers need to worry about their jobs? No. Copilot can help with tricky code constructs but doesn't help you add business logic. In the future, I could see an LLM interpreting a data model based on table and column names and having the ability to write queries to service reports. However, that depends on having well-defined table and column names and the LLM making significant assumptions based on your business rules. Yes, the models will improve over time, but many legacy databases will continue to exist and have terrible naming conventions that make little sense, even to humans.
The Future
You have learned about the current state of the art for AI in database systems. What is the potential for the future? I see a mix of both simple and complex operations -- automatically creating indexes and reverting bad execution plans is already here. Still, I think you will see those options continue to improve over time. I can also foresee hardware changes making the cost of execution plan creation much lower, which could lead to more optimal execution plans for every execution of a given query. Generative AI will change many things about how computing takes place in unexpected ways. Finally, read up on vector databases if you want to learn about AI systems and how they store their data.
About the Author
Joseph D'Antoni is an Architect and SQL Server MVP with over two decades of experience working in both Fortune 500 and smaller firms. He holds a BS in Computer Information Systems from Louisiana Tech University and an MBA from North Carolina State University. He is a Microsoft Data Platform MVP and VMware vExpert. He is a frequent speaker at PASS Summit, Ignite, Code Camps, and SQL Saturday events around the world.