Joey on SQL Server
Keep the Lights On: Dealing with Systems Failure as a DBA
It's not enough to have a backup-and-recovery plan. Today's IT pros need to practice salesmanship and PR savvy to get through a disaster.
- By Joey D'Antoni
- 04/03/2019
Computers are a part of our everyday life and, as such, so are computer disasters.
As data professionals, we are on the front lines of resolving those problems and getting the proverbial lights back on. As database professionals, the key parts of our tasks in a disaster are making sure backups and secondary systems are in place, and getting those into place after whatever bad thing happens.
While getting data restored is critically important and an undervalued skill, it is not the most important part of your disaster recovery plan. Yes, my DBA friends, I said your restores are not the most critical part of disaster recovery (though for technical reasons, they still are). The public relations side of managing a disaster is equally important.
When I had the initial thought to write this column, I had planned to focus on the recent outage at Wells Fargo and how it was handled. We'll get back to everyone's favorite bank later. However, this morning one of my co-workers tried to buy tickets for the soon-to-be-released "Avengers" movie, when this happened:
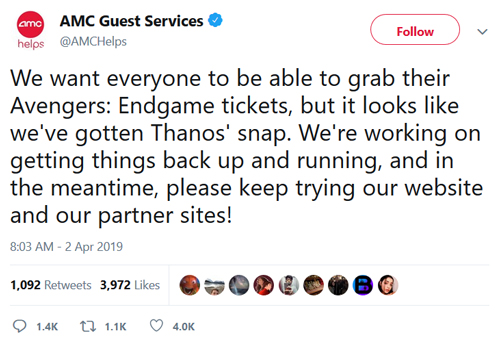
To use an oft-quoted line from movie trailers, in a world where we have three major public clouds that offer a vast array of enterprise services that most large (and even many small) businesses are able to afford, there is very little reason to have a public-facing outage in 2019. But here we are.
Many businesses decide to forgo any sort of disaster recovery investment, and frequently rely on "hopes and prayers" for high availability. However, there are well-known design patterns for how to make your systems and applications more reliable. For example, AMC could have used an auto-scaling Web tier in conjunction with a queuing system for handling database calls, keeping its service up through even the biggest workloads. Alas, it did not, and it had an outage on a big day.
The question remains: How do you, the technology professional, execute when your employer doesn't want to?
Promote the Risk from Within
When you signed up to be an IT professional, you were hoping to be avoid being a sales representative, right? Well, if you don't advocate for the health of your systems, data and applications, it is likely no one else in your organization will.
This isn't as simple as just shouting from the rooftops about your availability needs. You will need to make a business case as to why a given system requires the level of uptime you think it needs. Chances are the "Angry Birds" server won't have real-time synchronous failover to two datacenters and three cloud regions. Your job is to take these concepts and translate them into a business case.
Give a few options for availability. I always like to offer a low-, medium- and high-cost option. The low-cost option is usually putting backups into a cloud (maybe even to two regions) and the high-cost option is real-time failover to another geographic region. This is a good opportunity to take advantage of the public cloud; almost every low-cost disaster recovery option involves the cloud in some way.
When you are making this case, in addition to honing your systems architect skills, you are also providing some coverage for yourself by establishing a paper and e-mail trail with your suggestions. This can be tricky to do within an organization, but you need to ensure that if you are recommending something critical like backups or adding redundancy for a critical system, you have a record of your manager or their manager saying, "No, we really don't need those backups." There are even potential legal ramifications depending on your industry, but you will always be more protected with a document trail. While e-mail is a good paper trail, it's also important to have an offline record.
This is a matter of self-preservation. Systems will fail, and you (and your managers) hope that the failure won't be too bad and that whatever fails will have limited impact. However, if your entire enterprise gets ransomware-ed and you don't have offsite backups, it's nice to have that paper trail showing that you recommended the right thing to do.
My other honest bit of feedback is that if you are in a scenario where you must frequently document your management's decisions to protect their business, it might be in your best interest to find another job.
The Other Side of Disaster Recovery
The other piece of this, one that goes beyond the scope of the IT professional, is managing the PR side of your outage.
Outages are going to happen to your (and every) organization. Just like you need to be able to restore from backup, you need to have a communications plan for how you are going to communicate your status to customers, both internal and external.
This process could be as simple as having a static Web page that communicates your status, or as complex as a real-time status dashboard (just don't make it dependent on your other services being online, like Amazon Web Services has done) and a social media team sending messages out.
This is one place where Wells Fargo had problems. The bank had a datacenter fire, but instead of addressing the core issue, its PR team pointed the public to a nonexistent security issue:
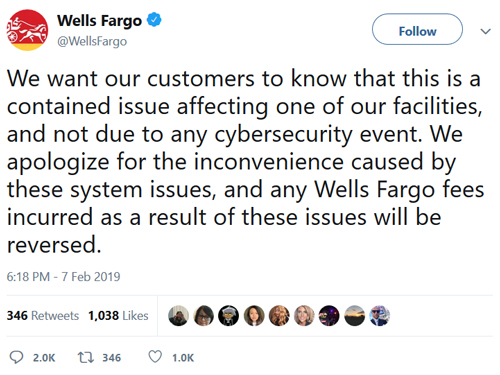
This is the wrong way to do PR. While this is not the role of IT professionals, you should still work with your management team to ensure you have input in its communications so that your public-facing messaging is realistic.
As an individual contributor in a technology organization, you may feel as though these topics are above your pay grade -- and in many cases, that is accurate. However, if you are looking to level-up your career or simply do what is right for your organization, building skills around system availability and selling your ideas to management will come in handy.
The PR side of IT disasters is still a work in progress; there's nothing you can download from GitHub to explain to your customers why their bank accounts are unavailable. Having professional staff and being honest with your customers will go a long way.
About the Author
Joseph D'Antoni is an Architect and SQL Server MVP with over two decades of experience working in both Fortune 500 and smaller firms. He holds a BS in Computer Information Systems from Louisiana Tech University and an MBA from North Carolina State University. He is a Microsoft Data Platform MVP and VMware vExpert. He is a frequent speaker at PASS Summit, Ignite, Code Camps, and SQL Saturday events around the world.