Joey on SQL Server
Containers: The Future of Database Infrastructure?
Databases usually lag behind other servers in moving to new architecture, but containerization brings enough major improvements to convince even the most old-school DBAs.
- By Joey D'Antoni
- 05/02/2018
When Microsoft announced back in 2016 that it was going to deploy SQL Server on Linux, buried in the announcement was support for containers -- specifically, Docker.
The other major component is Kubernetes, colloquially known as "K8s," the open source container orchestration solution that was developed at Google (where it was called "the borg"). Kubernetes is defined as "an operating system for the datacenter." Windows admins might want to think of this like Windows Server Failover Cluster and Hyper-V rolled into one management system for containers.
For those of you who are less familiar with containerization, the easy way for me to describe it is the next generation of virtualization. Unlike virtual machines (VMs), containers do not contain a full copy of the guest operating system. This means that the "hypervisor" operating system needs to share the same platform as the guest operating system. Containers are much smaller than VMs and allow application code and libraries to be deployed as a unit, in conjunction with any dependencies that the application requires. This means they become a developer's unit of deployment. This simple integration is why Docker and Kubernetes have become so popular in continuous integration/continuous deployment (CI/CD) workflows.
The other major benefit of a container orchestrator like Kubernetes is the level of automation it offers around scale-out and service healing. More than any service, containers truly bring the notion of "infrastructure as code" to fruition. While Windows, via PowerShell, and both Microsoft Azure and Amazon Web Services (AWS) allow machines to be defined as scripts, Kubernetes takes this one step further and has all underlying infrastructure defined in a script, which is known as a manifest. In your manifest, you define the service, the storage, the image (what software is running on your container) and any parameter that you need to define in order to complete deployment. Kubernetes does it better because it offers a single common platform for defining your services and containers.
What this means in reality is that your containers will run on Linux, as the major container platforms are using Linux as their base operating system. In fact, I wonder if the recent restructuring at Microsoft around Windows Server had to do with the surge in popularity of containers. Microsoft made some early efforts around containerization with Nano Server, but those efforts were not very fruitful. In Azure, however, Microsoft has launched Azure Container Service and Kubernetes services, which allow customers to get started with containers with minimal infrastructure and time investment.
But the Database Servers? Really?
Much like the early days of virtualization, database servers are not typically the first group of servers to move into new architecture. This is for several reasons. The database is the core of many applications and may contain valuable information supporting things like product catalogs and recording sales transactions. Containers are becoming a major force in application development, but -- particularly in large enterprises -- on-premises database systems still largely run in VMs or physical servers.
Containers will see similar challenges. In the world of SQL Server, there are a couple of current limitations that will prevent widespread adoption, namely a lack of Active Directory authentication and Always-On Availability Groups for disaster recovery. Microsoft is working on these features and I would be surprised if they were not in the next release of SQL Server, if not in a cumulative update.
Containerization offers a couple of major improvements to the way we build database servers, however. Let's take a look at the architecture of running SQL Server 2017 in a highly available Kubernetes environment.
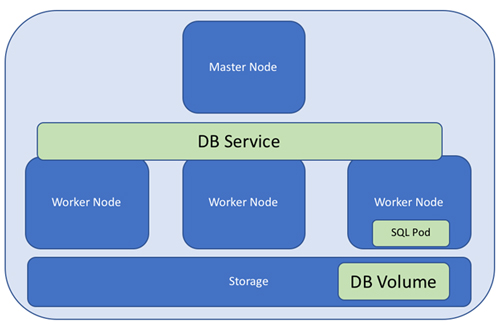 Figure 1
Figure 1
Figure 1 above shows both the hardware and software architecture of SQL Server running on Kubernetes. The cluster contains a master node and three worker nodes (worker nodes were formerly known as minions; you may still see this nomenclature). The master node manages resources, performs operations like service healing, and can be made highly available. The worker nodes run the pods (pods can be a group of containers, but in the current SQL Server configuration are a single container).
Storage is presented to all nodes of the cluster. In order to persist the storage for SQL Server, you will define a persistent volume claim. In doing this, you are separating storage from compute, which is one of the major benefits of this architecture. With this separation, you can scale both storage performance and capacity, independent of compute, which is a huge bonus.
Built-In High-Availability
The other major benefit is that this configuration automatically delivers high availability to the configuration -- the functional equivalent of a SQL Server failover cluster instance, without the idle hardware. Once you have defined your container as part of a service, in the event of failure, Kubernetes' service healing will spin up a new container. Since the storage is persisted, any transactions will be retained and crash recovery will be performed when the new container comes online and talks to the data files that are in the persisted volume.
In the configuration defined in books online, Microsoft references the SQL Server Docker image. Many Kubernetes users still use Docker repositories for their images. However, you may specify a specific cumulative update level. This allows DBAs to perform a rolling update by changing the patch level in the manifest and simply redeploying the manifest. The original container is then terminated and a new one spun up on the new release level, with a minimal amount of downtime.
The large-scale shift from physical machines happened over about a 10-year period; I don't foresee the movement to containers being that protracted. IT organizations have already accepted virtualization, so the switch is not nearly as big, it enables many automation scenarios, and the biggest factor is that it has the potential to reduce cloud costs by increasing densities. This will not be a major shift for database professionals, but they should get in front of the technology by having a good understanding of how it works with their platforms.
About the Author
Joseph D'Antoni is an Architect and SQL Server MVP with over two decades of experience working in both Fortune 500 and smaller firms. He holds a BS in Computer Information Systems from Louisiana Tech University and an MBA from North Carolina State University. He is a Microsoft Data Platform MVP and VMware vExpert. He is a frequent speaker at PASS Summit, Ignite, Code Camps, and SQL Saturday events around the world.