Microsoft Releases Video and Speaker Recognition APIs
Microsoft today said its Speaker Recognition APIs and Video APIs are now available in public preview and said the company is accepting invites to those wanting to test its forthcoming speech-to-text service. The new APIs are the latest milestone by Microsoft Research to make machine learning mainstream under its Project Oxford effort.
The first Project Oxford APIs, designed for facial recognition, debuted last month. And like those, the newest interfaces allow developers to add functionality with just a few lines of code, according to Microsoft. When Microsoft released the facial recognition APIs, the company said it would also follow suit with the speaker recognition, video and text-to-speech APIs by year's end.
Those wanting to test Microsoft's speech to text service, called Custom Recognition Intelligence Service (CRIS), can register at www.ProjectOxford.ai.
As the name implies, the Speaker Recognition APIs can determine who is speaking based on their voice. Microsoft warns that the Speaker Recognition APIs shouldn't be used in place of stronger authentication methods -- they are suited for two-factor authentication used with a password, PIN or a physical device such as a keypad, smartphone or credit card. More practically though, it appears the company is aiming them more toward customer service-oriented functions.
"Our goal with Speaker Recognition is to help developers build intelligent authentication mechanisms capable of balancing between convenience and fraud," said Ryan Galgon, senior program manager at Microsoft Technology and Research, in a blog post announcing the new APIs. "Achieving such balance is no easy feat."
Galgon noted that the speaker recognition APIs learn specific voices during the enrollment. "During enrollment, a speaker's voice is recorded and a number of features are extracted to form a unique voiceprint that uniquely identifies an individual," Galgon noted. "These characteristics are based on the physical configuration of a speaker's mouth and throat, and can be expressed as a mathematical formula. During recognition, the speech sample provided is compared against the previously created voiceprint.
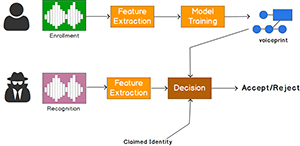 [Click on image for larger view.] Courtesy: Microsoft
[Click on image for larger view.] Courtesy: Microsoft
Meanwhile, the video APIs use processing algorithms for those editing videos. It will automate functions such as stabilizing videos, detecting faces and use motion detection on a frame-by-frame basis. Microsoft said the service improves the video editing process by reducing false positives by ignoring shadows and changes to lighting.
Posted by Jeffrey Schwartz on 12/14/2015