Joey on SQL Server
Deep Dive into SQL Server 2022's Query Performance Features, Part 2: PSP Optimization
Reduce workload times with this handy feature that can benefit every database pro.
- By Joey D'Antoni
- 11/09/2022
In part 1 of my SQL Server 2022 features series, you learned about the improvements to the cardinality estimator component of query optimization. In this installment, you will learn about another common performance problem: parameter sensitive plans.
The process of query optimization is very computationally expensive. For this reason, SQL Server stores execution plans in a cache (called the plan cache), so that the stored execution plan is reused for subsequent executions of a given query. These cached execution plans are optimized for the parameter that was initially passed in. For example:
CREATE OR ALTER PROCEDURE [Warehouse].[GetStockItemsbySupplier] @SupplierID int
AS
BEGIN
SELECT StockItemID, SupplierID, StockItemName, TaxRate, LeadTimeDays
FROM Warehouse.StockItems s
WHERE SupplierID = @SupplierID
ORDER BY StockItemName;
END;
GO
EXEC Warehouse.GetStockItemsbySupplier 2;
GO
The execution plan would get created based on the parameter value of 2, and subsequent executions use the same execution plan despite having different parameter values. This process is called parameter sniffing and is a net good, as frequent compilations of queries can cause excessive CPU usage. However, there may be times when a cached execution plan can be suboptimal for certain parameter values.
Have you ever had a query that occasionally ran slow, while other times running perfectly? While there are many reasons why this can happen, one common reason is that a query execution plan is created for a parameter used when the query was compiled and is suboptimal for other values. This is typically caused by data skew. For example, if you had a column that had integer values from 1 to 1,000,000, and then had ten million records with the value of 1,000,001, depending on if your first parameter is 1, or 1,000,001, your query execution plan will be quite different.
Traditionally fixing these problems was a challenge -- the best fix is to restructure your tables in order to eliminate data skew, which requires development effort and, in some changes, breaking changes. In the database you could create filtered indexes. In the above example, you would likely want to exclude the 1,000,001 values. However, filtered indexes have some limitations -- the biggest being that they don't work with parametrized code. This a common performance problem. So common that many developers and DBAs think parameter sniffing is a performance problem.
Using the above stored procedure and look at the distribution of records in the underlying table, you can see that there is a large amount of data skew:
| SupplierID |
Supplier Count |
| 5 |
4000042 |
| 4 |
3999847 |
| 7 |
67 |
| 10 |
18 |
| 12 |
15 |
| 1 |
8 |
| 2 |
3 |
|
What this means is that the best execution plan for a parameter value of 1 or 2 would be for SQL Server to do an index seek operation against the SupplierID column (which happens to be indexed here), and the best plan for a SupplierID of 4 or 5 would be an index scan. You should note that this is rather extreme data skew issue created for the purposes if this demo, and if you have tables that look like this, you should really evaluate your data architecture.
In older versions of SQL Server (or SQL Server 2022 without compatibility mode 160 in place), you would see only one execution plan cached for the execution of this stored procedure. With the parameter sensitive plan (PSP) optimization feature, the engine can cache multiple execution plans based on the value of the parameter at execution. The way this works is that during the initial process of query optimization, the engine evaluates column statistic histogram options (remember part 1 of this series on cardinality estimation) and looks for "at-risk" parameter values in predicates, up to three different values.
For each of those predicate values, the query processor places each of them into buckets and places them into ranges. A new component of execution plans which refers to the dispatcher highlights this and directs the query based on the predicate value into a specific query plan. This is not dissimilar to an approach that many developers took to avoid this problem in the past: using nested stored procedures based on the value of the input parameter, except that it's built into the optimizer.
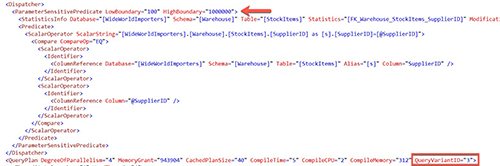 [Click on image for larger view.] Figure 1.
[Click on image for larger view.] Figure 1.
The plan XML above, shows the highlighted range value. This process works in a manner that is similar (but different) than forced execution plans in query store. Additionally, you can see QueryVariantID in the query plan element of the XML which allows you to identity which variant was used. The query store is not required for the use of PSP optimization process, but it does give you deeper insights into how the optimization process is working. Just to give a better example, I used a demo provided by Bob Ward, from Microsoft, to test out the performance gains introduced by PSP optimization. This example provides for a rather dramatic improvement in overall performance.
| Compatibility Level |
Elapsed Time |
| 150 |
00:23:02 |
| 160 |
00:00:06 |
|
Yes, you read that correctly, the time to complete this test went from 23 minutes to just over six seconds! To dig a little bit deeper into the methodology, I changed the compatibility level of the database from 160, back to 150 to start the test. Which would have flushed the execution plan cache. I then executed the procedure with the parameter of 4, which would cause the scan plan to be cached. I then used one of batch scripts in Bob's code to execute 10 threads of the plan with a parameter of 2, which would be negatively impacted by the seek plan. However it wasn't just the shape of the execution plan that was problematic; the memory grant associated with the query was such that most of those threads were waiting on memory to be granted (I ran this demo on Azure VM with 16 GB of RAM). Most of that time wasn't spent executing the queries, it was the query waiting for a large, unneeded memory grant.
When I changed compatibility mode back to 160, I repeated the test process. The big difference was the database engine being able to maintain multiple plans for the same query. In each test, the scan query takes about 5.5 seconds to complete. However the same ten threads of the seek query took 22:57 to complete in compatibility mode 150, while only taking 522 milliseconds in 160. While this demo illustrates a rather extreme example of data skew, you can imagine the benefits for many production workloads.
There are a lot of useful features in SQL Server 2022, some of them are little more niche than others. However, parameter sensitive plan optimization is a feature that can broadly benefit nearly all SQL Server workloads. When you combine that with the improvements to cardinality estimation introduced in the first part of this series, you can begin to see the major performance improvements your application can see just by upgrading to SQL Server 2022 and changing your database compatibility level to 160.
About the Author
Joseph D'Antoni is an Architect and SQL Server MVP with over two decades of experience working in both Fortune 500 and smaller firms. He holds a BS in Computer Information Systems from Louisiana Tech University and an MBA from North Carolina State University. He is a Microsoft Data Platform MVP and VMware vExpert. He is a frequent speaker at PASS Summit, Ignite, Code Camps, and SQL Saturday events around the world.