News
Azure Data Lake Service for Big Data Analyses Now Available
Microsoft this week released Azure Data Lake as a generally available (GA), production-ready service, backed by Microsoft's 99.9 percent service-level agreement.
Azure Data Lake is a service for "Big Data" massively parallel types of analyses, with the ability to tap into pools of structured and unstructured data without limits. The service has been at the preview stage since November of 2015, according to a Microsoft Channel 9 presentation, so it's taken one year to arrive fully baked.
Microsoft is marketing the Azure Data Lake service as enabling "Big Cognition." The idea is glean insights from multiple inputs of various data types. It's about "joining all the extracted cognitive data with other types of data, so you can do some really powerful analytics with it," according to a Microsoft announcement.
Azure Data Lake Components
Azure Data Lake is composed of three Azure services, according to the presentation. It has HDInsight, which is Microsoft's Hadoop-based Big Data service. Another component is the new Data Lake Store (GA this week), a repository for structured and unstructured data that can scale to meet developer needs. Lastly, there's the new Data Lake Analytics (GA this week), which permits users to run "massively parallel data transformation and processing programs in U-SQL, R, Python and .NET over petabytes of data," per the announcement.
The overall system is based on the open Apache Hadoop Distributed File System. Microsoft illustrates the Azure Data Lake components in the following diagram:
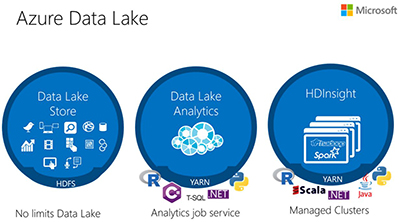 [Click on image for larger view.]
Azure Data Lake components. Source: Microsoft blog post.
[Click on image for larger view.]
Azure Data Lake components. Source: Microsoft blog post.
The U-SQL query language is frequently mentioned in Microsoft's Azure Data Lake announcements. It may seem new, but Microsoft has been using U-SQL internally since 2008, according to the Channel 9 presentation. U-SQL is supported in Azure Data Lake Tools for Visual Studio Code at the preview stage and "combines the declarative advantage of T-SQL and extensibility of C#."
A Reddit Ask Me Anything session conducted by Microsoft Azure team members this week offered an additional definition of U-SQL, as follows:
It [U-SQL] has an official meaning which is that it unifies:
- structured and unstructured data processing
- declarative SQL with user code (written in C#, Python, R etc.)
- querying data in Azure Data Lake with querying data from Windows Azure Blog Store, SQL Server in Azure
The inofficial meaning is that you need a submarine to explore the depth of your data lake and discover your treasures. And in German and Swedish, submarines are called U-Boot :).
It is not true that it is called U-SQL because the U comes after the T.
Developers love the U-SQL query language and pick it up very fast, according to Microsoft's presentation. Microsoft offers a tutorial here.
Spinning up an Azure Data Lake workload takes "30 seconds," Microsoft claims. Essentially, Microsoft takes care of managing the cluster for developers or data scientists. Additionally, Data Lake Store is designed to have "no limits" on the data size or the number of files or objects used in the analysis. No repartitioning of the data is required to run analyses. Developers don't have to define a schema up front.
In addition, Azure Data Lake is integrated with Azure Active Directory. It has role-based access controls over the Data Lake Store via "POSIX-based ACLs for all data" or "Apache Ranger in HDInsight," Microsoft's announcement explained. Organizations have single sign-on and multifactor authentication access options. Data are encrypted at rest via the service or Azure Key Vault. Data are encrypted in motion using the Secure Sockets Layer protocol.
Azure HDInsight Support
Microsoft also announced some additions to Azure HDInsight this week. One addition is R Server for HDInsight, which is now generally available. It's Microsoft's implementation of the R programming language "integrated with Spark clusters created from HDInsight," which can process terabytes of data. When it is run on Apache Spark, R Server "enables handling up to 1000x more data and up to 50x faster speeds than open source R," Microsoft claimed. A new capability is the ability to work with Spark SQL data sources. It's supported for developers and data scientists with an included R Studio Server Community Edition, but they can also use R Tools for Visual Studio.
Microsoft also issued a preview of the open source Kafka for HDInsight. It's designed to enable the ingestion of "massive amounts of real-time data." It can be used for operations such as "fraud detection, click-stream analysis, financial alerts, or social analytics solutions," the announcement indicated. It's also designed to work with Storm for HDInsight or Spark Stream for HDInsight stream analytics solutions.
About the Author
Kurt Mackie is senior news producer for 1105 Media's Converge360 group.