In-Depth
Fixing Active Directory Disasters: A How-To Guide
Spotting Active Directory problems isn't necessarily simple, but it can help avoid a catastrophe. These tales of AD disasters come from real-life situations and should serve as instruction -- and perhaps a warning -- to IT pros.
Ever since Windows 2000 introduced Active Directory, disaster recovery has been a hot topic among administrators. There has been no shortage of methods, tools and opinions about how to prevent a domain or forest collapse that might shut down a business and cause an IT professional to lose his job. Disaster recovery certainly has evolved with improvements and efficiencies in core AD components; replication, design implementations and the overall user experience have improved.
Over the years, I've been involved in a number of cases where some form of AD disaster occurred and a recovery was required. In this article, I'll describe several of these episodes, working from the not-so-serious scenarios to the worst-case incident, where all domain controllers (DCs) in a parent domain of a multi-domain forest went down, and the backup was 11 months old!
Replication Disaster
In the first case, the architect of an AD topology wanted a tiered topology to reflect his network. He had three core sites in New York and Los Angeles connected with a dedicated, high-speed network link. For the next tier, there were four regional sites in Omaha, Dallas, Atlanta and Providence. Each of the regions had two sub-region sites. The plan was to make three tiers -- the core, region and sub-regions so that the sub-regions replicated, then replicated up to the region sites; the region sites replicated up to the core; the cores replicated to each other. This was designed to take advantage of the network topology.
Unfortunately, the topology wouldn't work. One of the rules in replication design is that links must have common sites to replicate. For instance, you can't have a site link with Washington, D.C., and Raleigh and another with Dallas and Topeka. You'd need to add a link with Raleigh and Dallas, for example.
In this case, the IT pros put the region headquarter sites in Omaha (OMH), Dallas (DAL), Atlanta (ATL) and Providence (PRO) in both the second- and third-tier links (see Figure 1). For instance, the OMH site was part of the Midwest Link and the West Link. Similarly, the Los Angeles core site was in the East Region Link and the Core Link site links. This would provide the glue that allows replication to flow from third-tier sites to the core sites.
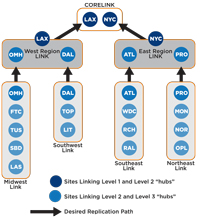
[Click on image for larger view.] |
| Figure 1. The initial topology, shown here, eventually broke down |
This design actually worked until a DC in the OMH site had a disk failure. Note that this was the "glue" site that hooked the other sites to the East Region sites, and with site-link bridging enabled, the Knowledge Consistency Checker (KCC) was able to recover from the OMH DC loss. However, when the OMH DC was restored, the KCC had picked the Tucson (TUS) DC to replicate to for the second level. This caused all the Midwest Link DCs to replicate to the TUS DC rather than OMH. That disrupted the whole replication design, which was based on network speed and reliability.
The only way the IT people could restore the replication flow was to wipe and reinstall the OMH DC. A few weeks later, the ATL DC failed, and the KCC picked the Richmond (RCH) DC for the ATL link DCs to replicate to. Again, the only way to get replication back to the way they wanted it was to reinstall the ATL DC. They were understandably concerned about having to reinstall any DC that went offline for a few days. In addition, some other DCs in other regions started replicating to all DCs in the forest. There were replication errors, and network traffic on some DCs took a huge spike -- it was quite a mess.
I really didn't have an explanation for this behavior, other than the KCC picking the lowest-number GUID. They had given the KCC too much freedom to choose by putting more than two sites in a site link. The solution was to delete all the site links and recreate them with no more than two sites per link. The Midwest Link was replaced with the OMH-FTC link, OMH-TUS link and so on (see Figure 2). The West Region Link was replaced with the OMH-LAX Link, as well as individual links from each region headquarter site to either LAX or NYC site, depending on their geography.
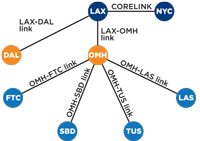
[Click on image for larger view.] |
| Figure 2. The solution to the replication problem was simplifying the design -- creating a 1:1 relationship between the OMH site in the second-level replication tier and the third-level sites FTC, SBD, TUS and LAS. This forces the KCC to replicate between only two sites at a time and not have to make a decision. |
The administrator decided to just reconfigure one region. To test it, he removed a DC and put it back in, and replication continued as designed. He reconfigured the rest of the forest, and the replication problems all went away. The important thing here is that he did this during business hours. OK, replication was probably broken for a couple of cycles -- but it did no harm. Replication was pretty resilient. There was no need to reboot, no disruption to the users.
SOLUTION: Pay attention to the AD topology design and follow the rules noted here. But remember, even if it's wrong, it can easily be fixed.
Virtual Disaster
In another situation, a perfectly logical disaster recovery plan for two virtual DCs was designed and implemented, which caused the disaster. In this case, there were two physical servers, each running a virtual DC (see Figure 3). So, the DC was really a virtual hard disk (VHD) -- a file on the physical disk.
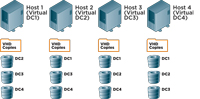
[Click on image for larger view.] |
| Figure 3. A configuration with two physical servers, each running a virtual DC.
I've seen several cases where "somehow the SYSVOL structure was deleted." Honest! I can't imagine how this is anything but human error -- maybe trying to "clean things up." |
The IT pros at this organization made a backup each night of the physical host. Because the VHD files could be copied and moved to other locations, the administrator reasoned that he could copy the datacenter 1 (DC1) VHD file to DC2 and the DC2 VHD file to DC1. They repeated this strategy for DC3 and DC4 so that in the end, if DC1 went down, they could restore it by copying the DC1 VHD from DC2 (or DC3 or DC4) back to DC1 or a new server and be back in business. They did not backup the DCs in their own OS -- they just backed up the physical host. Note that restoring the VHD will vary depending on your virtual machine (VM)software, but that's not the point. This situation points out the flaws in the design.
Satisfied their plan was safe, the admins decided to test the recovery. Reproducing this in the lab, they removed the existing VM/VHD from DC1 and built a new one using the DC1 VM/VHD that was stored on DC2. It failed, but that wasn't immediately obvious. It seemed to replicate, but updates weren't showing up, and their peers were finding other anomalies as well.
They had discovered the effects of an unintentional USN rollback, rolling the AD on DC1 back to the previous day. There's nothing wrong with this if you do it right. However, the admins in this situation violated a few very important rules:
- Never restore a DC from a snapshot image. The VHD is a snapshot image, but there are other ways to do this.
- Never back up a DC by backing up the VHD file on the host computer. It can't be successfully restored.
- Always back up the System State of a virtual DC (in the VM itself) using an "Active Directory Aware" backup and restoration utility. This will reset the Invocation ID of the AD database and will keep all versions of the database on all the DCs in sync.
The unintentional USN rollback is hard to detect and has only one repair: rebuild the DC. It basically creates a gap in the database transactions on the rolled-back DC. So other DCs think the transactions (adding, modifying, deleting an object) have been replicated to the problem DC and they don't replicate it again. The broken DC doesn't have the objects and will never be notified to get them. A stalemate occurs.
SOLUTION: Prevent this disaster by reading Microsoft KB 875495. Be sure to understand the causes and effects of unintentional USN rollback and how to recognize the situation. Further, follow the rules noted in this article and in the KB to prevent this situation from happening.
Deleted FRS File Structure
This is not all that common, but it does happen. It's disastrous and quite easy to do. The result is losing all Group Policies on all DCs. Not a good career move. I'm sure most of you reading this article have been convinced of the futility of getting File Replication Service (FRS) to work reliably and have upgraded to 2008 and migrated to Distributed File System Replication (DFSR). For those unfortunate souls who are still bound with FRS, here's a great way to restore this.
Because FRS is multimaster replication (it actually relies on AD Replication), it's pretty easy to have a mistake replicated quickly. I have seen a number of cases where FRS was hosed. In one case, the admin was afraid of losing his group policies due to FRS folders vanishing, so he copied the SYSVOL tree to the desktop of his DC. This effectively created a new junction point, and it was replicating to both SYSVOL trees on that machine -- it was like two DCs in one. To solve this, we had to carefully delete the junction point (not the folder). Deleting the SYSVOL folders will replicate and will delete them on all DCs!
I have seen several cases where "somehow the SYSVOL structure was deleted." Honest! I can't imagine how this is anything but human error -- maybe trying to "clean things up." The danger, of course, is losing all your Group Policies; hopefully you have them backed up. Remember to back them up using the Group Policy Management Console (GPMC) or any number of third-party tools, or simply by copying them from the SYSVOL tree to some other location outside of SYSVOL.
If a SYSVOL folder becomes corrupt or for some reason just one DC can't get in sync, it's easy to do either the non-authoritative or authoritative restore, where you sync the broken machine up with a good DC. Microsoft KB 315457 is a good reference for this.
However, restoring the whole file structure is quite another matter. KB 315457 is mostly correct for this scenario, but I found a few gotchas with the linkd command. Of course, demoting (manually if necessary) and re-promoting is always the short answer, but if that isn't an option, here's a procedure that will work to get the junction points restored properly. I will assume you understand the SYSVOL structure, but as a reminder, SYSVOL/Domain/Staging Areas/mydomain.com and SYSVOL/SYSVOL/mydomain.com are the junction points pointing to the real directories of SYSVOL/Domain/Staging/Domain and SYSVOL/Domain, respectively.
SOLUTIONS: 1. How to recreate SYSVOL and junction points when SYSVOL has been deleted from all DCs:
- Stop the FRS service on all DCs.
- Create the SYSVOL folder tree manually (This is the FQDN of your domain):
SYSVOL
Domain
DO_NOT_REMOVE_NtFrs_PreInstall_Directory
Policies
Staging Areas
Staging\Domain
SYSVOL
Mydomain.com
- Set the ACLs on the "DO_NOT_REMOVE_NtFrs_PreInstall_Directory":
- Administrators (domain admins) and System both set to ONLY have "Special Permissions."
- Set the "DO_NOT_REMOVE..." directory as Hidden and Read only.
- Create the junction points. Make sure the FRS is stopped on the DC this is executed on:
linkd "%systemroot%\SYSVOL\SYSVOL\mydomain.com"
%SYSTEMROOT\SYSVOL\DOMAIN
linkd "%systemroot%\Sysvol\staging areas\mydomain.com"
%systemroot\sysvol\Staging\Domain
NOTE: If SYSVOL is not stored on the Windows System Disk, replace C:\Windows in the linkd command to reflect the path to SYSVOL.
- How to Build the Default Domain Policy and Default Domain Controller Policy:
- If you don't have backups of the Default Domain Controller Policy or the Default Domain Policy, then from the command line of the Primary Domain Controller, run Microsoft's DCGPOFIX tool. See KB 833783.
WARNING: This tool will create a virgin Default Domain Policy and Default Domain Controller Policy -- don't use this if you have a copy of these policies somewhere. If you do have backups, simply restore them to the proper location in SYSVOL.
- It will prompt you to restore the Default Domain Policy and will ask if you want to restore the Default Domain Controller Policy. You should answer "Yes" to both of the questions.
- Replicate SYSVOL for this DC by starting FRS:
C:>net Start "File Replication Service"
NOTE: Do NOT use the Burflags procedure. This can cause the SYSVOL directory to disappear.
- Make sure FRS is working. TIP: create a text file such as DC1.txt (on DC1) in the SYSVOL\SYSVOL directory (so it's easy to find). Let replication take place. This file should end up in this location on all DCs. Any DC without it is not replicating FRS properly. Remember this could be due to AD Replication failure as well.
2. How to recreate junction points if the SYSVOL tree exists but junction points don't exist:
- Stop FRS:
C:>Net Stop "File Replication Service"
- Create the junction points. Make sure FRS is stopped on the DC:
linkd "%systemroot%\SYSVOL\SYSVOL\mydomain.
com" %SYSTEMROOT\SYSVOL\DOMAIN
linkd "%systemroot%\Sysvol\staging areas\mydomain.com"
%systemroot \sysvol\Staging\Domain
NOTE: If SYSVOL isn't stored on the Windows System Disk, replace C:\Windows in the linkd command to reflect the path to SYSVOL.
Lingering Objects
No AD disaster recovery discussion would be complete without a section on Lingering Objects (LOs). LOs are more a result of some disaster but can also cause a lot of headaches for IT pros. I've found a number of environments where LOs exist -- and have existed for some time -- but have never been cleaned up. This is likely due to the fact that AD still works except for anomalies such as objects showing up in one domain and not in another. It's hard to clean them up, and it mostly applies to multiple domain forests. To make a long story short, LOs are caused by a DC being inaccessible by other DCs for longer than the tombstone lifetime (TSL) and then coming back online. The TSL defaults vary based on the version of Windows you're using and are customizable. If the DC comes online after deleted objects have been purged by garbage collection (GC), having expired the TSL, it can replicate those objects back to healthy DCs and reanimate the objects. Typically, this will be a problem on the GCs when read-only objects are replicated back.
Events 1864, 2042 and 1988 in the Directory Services event log are good indicators of LOs. You can see messages in event logs and Repadmin/showrepl output.
When LOs try to get replicated, it can trigger replication to stop between two DCs. If the very important "StrictReplicationConsistency" registry key is set to (1), which means Strict behavior, and if a replication partner wants to modify an object that doesn't exist on the DC, all replication will be shut off. A very helpful message to this effect will show up when executing the Repadmin/Showrepl command, the DirSvcs Event Log, Repadmin/Replsum, and other reports and logs:
The Active Directory cannot replicate with this server
because the time since the last replication with this server
has exceeded the tombstone lifetime.
There are other messages that are pretty obvious. This is good! It isolates the bad machine so you don't have to clean up all the DCs. I've seen many environments where this registry key is set to "loose" (0) which means the DCs will replicate LOs. Not good. If you have an environment that started out with Windows 2000 and has been upgraded (as opposed to a fresh install of the entire forest) to Windows 2003, 2008, etc, then this setting is probably set to "loose" as that was the default in Windows 2000. The key is located at:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\NTDS\
Parameters
ValueName = Strict Replication Consistency
Thanks to some diligent work on Microsoft's part, LOs went from being a hideous nightmare in Windows 2000 to being fairly easy to clean up in 2003 and later. The key tool is good ol' Repadmin and the /RemoveLingeringObjects switch. Can't find this option in the online help for Repadmin? Try Repadmin/ExpertHelp.
SOLUTION: If you have any Windows 2000 in your environment and they contain LOs, the solution is to replace (don't upgrade) them with Windows 2008 DCs (assuming you can't get Windows 2003).
For Windows 2003 and later, the short answer is:
- Set all DCs to StrictReplicationConsistency = 1. Failure to do this will allow the LOs to keep replicating. Use the Repadmin command to quickly set this on all DCs (add all the DCs in the DC_LIST; see the online help for Repadmin for details):
repadmin /regkey DC_LIST +strict
- Use the Repadmin /removeLingeringObject command:
Repadmin /removelingeringobjects <Dest_DC_LIST> <Source DC
GUID> <NC> [/ADVISORY_MODE]
- Dest_DC_List: list of DCs to operate on
- Source DC GUID – the DSA GUID of a reliable DC (preferably the PDC)
- NC – Naming context of the domain the lingering objects exist in
- /ADVISORY_MODE – identifies what will happen when you execute the command for real
So a sample command would be:
C:\>Repadmin /removeLingeringObjects wtec-dc1 f5cc63b8-cdc1
-4d43-8709-22b0e07b48d1 dc=wtec,dc=adapps,dc=hp,dc=com
This has to be done on all DCs in the forest and can easily be scripted.
Armageddon: Recovering a Forest When the Root Domain Goes Away with No Backup
This example is from an actual case I worked about a year ago. It was easy to see the glaring design error in this configuration. The root domain has only one DC (see Figure 4). I was called when the single DC in the root domain went down and the company's IT staff couldn't recover it. It had a RAID 5 disk but, as fate would have it, the IT folks lost two disks from the array. To make matters worse, the backup was 11 months old. A true disaster!
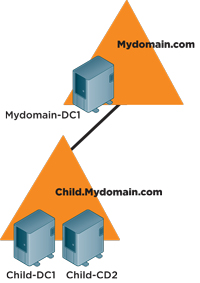
[Click on image for larger view.] |
| Figure 4. A root domain with only one DC led to disaster. |
The child domain had all the user accounts and interestingly, there was no user outage -- no complaints. My first thought was LOs, but becuase there were no other DCs, there could be no lingering objects in the domain. There could, however, be GCs in the child domain.
SOLUTION: The plan was designed:
- Set the tombstone lifetime to 365 days so we don't have to risk adding LOs. This is done via the ADSIEdit tool -- modify the TSL attribute at:
cn=Directory Service,cn=WindowsNT,cn=Services,
cn=Configuration, dc=mycomain,dc=com
- Restore the backup to the DC in the root domain.
- Set the system time on the DC in the forest domain to the current date/time
- Set StrictReplicationConsistency to 1 on all DCs
- "Demote" the GC in the child domain to a DC
- Do a health check:
- Event logs
- Validate the trust
- Logon from a machine in the root domain using an account in the child domain and vise versa
- Add test users and sites in each domain and see if they replicate to all DCs
- "Demote" the GC in the child domain to a DC
- Let replication take place and update the root DC
- Promote at least one DC to GC
- Check event logs for errors
- Build a second DC for the root domain
- Set the TSL to 180 days (minimum)
- Backup all DCs
Actually, we did all this in a lab first. Using the current backups of the child domain DCs and the old backup of the root domain DC, we reproduced the environment. Then we executed the procedure just described. The health check in the test environment actually turned up a few DNS errors -- unrelated to this procedure -- so we fixed those and some other issues in the production environment. At that point, we were confident that the restore would work, and it worked without incident. The interesting thing is that we did this during business hours and experienced no outages or complaints from users.
AD disasters are easy to cause, and not always easy to recover from. It's important for any AD administrator to be familiar with the warning signs and pay attention to logs and reports.
Pay attention and avoid disasters -- I hope these tips help!