In-Depth
Clouds Done Right
Cloud platforms might offer cost savings and other benefits, but they can also have costly bottleneck issues.
The promises of cloud computing are alluring: get rid of your data center, shrink the administration load, reduce backup expenses and put all the work on a service provider. Then reality sets in: Can the cloud handle high transaction volume and high-traffic applications?
Just look at many of your internal applications. They may start off small, but soon you're increasing traffic to your applications and scaling out the corresponding infrastructure regularly. And with all that comes performance and scalability bottlenecks.
Moving applications to the cloud doesn't magically make these bottlenecks go away. Nor does the cloud change the fundamental way most applications operate. Your application in the cloud will still use a traditional relational database for its application data. Therefore, you still have data storage scalability issues. And because it's seemingly so easy to increase the load on your application, these issues can get worse in the cloud.
The cloud is entering the tech marketplace at an interesting time. Web applications are becoming more and more popular, and therefore need scalability. New architectures and environments are being introduced, allowing applications to handle larger traffic and transaction loads. Cloud computing is a meaningful step toward that scalability -- if it's done right.
The cloud has two key benefits. First, it promises that users or application developers won't have to manage any IT environment. Secondly, the cloud can seamlessly scale an application's load, and in the process easily adjust the underlying infrastructure in terms of the number of servers running your application. You can quickly add servers during peak times and then drop them when the traffic declines. This ease of management makes it very tempting -- maybe too tempting -- to try to scale your application.
Peeking Inside Windows Azure
There are a number of cloud environments on the market, and more are coming from well-established vendors and start-ups. But for many Microsoft shops, Windows Azure will be a natural choice. Before taking the plunge, IT must find out what Azure offers in performance and scalability.
First off, you need to develop your applications to be compatible with the Windows Azure framework. In this framework, your application is segmented into services, and the services themselves contain roles. This is similar to service-oriented architecture (SOA), where an application is divided into services. In this case, you still have services, but every service has roles inside it.
Figure 1 shows a high-level breakdown of how a Windows Azure-compatible application needs to be architected. As shown in Figure 1, there are Web roles and worker roles. A Web role is a Web-application component accessible via an HTTP or an HTTPS endpoint-meaning some client application. This could be a browser, or it could be a custom application on the client end that could access this Web role via HTTP or HTTPS.
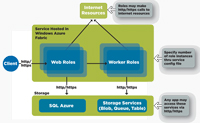
[Click on image for larger view.] |
| Figure 1. The Windows Azure application architecture. |
A Web role can then depend on worker roles, which are background-processing application components, whereas the Web role is the public interface. A worker role communicates with your storage services or with other Internet-based services. It doesn't expose any external endpoint, which means nobody from outside can call a worker role. Everybody has to call a Web role, and the Web role then calls a worker role.
Your application now consists of multiple services, and every service contains multiple roles. The roles are hosted by the service, and the client invokes or executes these roles with the Web role being the public interface.
This allows your application to run on as many servers as the cloud allows or as your needs require, because all the roles are stateless, meaning they don't remember data from previous calls. These roles rely on the storage services to hold all the state information. This allows a role instance to service a request that was previously serviced by another role instance on, perhaps, a different machine. These roles are service components that can run in parallel and provide scalability as far as the application architecture is concerned. But the issue eventually comes down to the weakest link in the chain. Although Windows Azure has a brilliant architecture, the weakest link is the storage services.
Storage Options in Windows Azure
Windows Azure has created a storage-services layer made up of three service types called blob, queue and table (see Figure 2). Both Web and worker roles can access these storage services. A blob is large, binary-object storage and can store large chunks of data, such as images, videos, documents and other non-relational data.
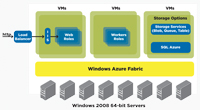
[Click on image for larger view.] |
| Figure 2. Application deployment in Windows Azure. |
A queue is used as a messaging mechanism for different roles to talk to each other. You can queue a message, and then other roles -- even those roles that are running on different machines -- can pick it up. This is a form of collaborative computing where one role is able to interact with other roles asynchronously.
The table storage type is intended to replace a relational database, in many cases by providing a relational data structure that can be partitioned and stored on multiple servers. From the outset, it appears to be a smart way of scaling relational storage because a partition key is assigned to each row of data along with a row key. This partition key is supposed to help Windows Azure distribute data on multiple locations for scalability.
From the outset, the storage services look incredibly powerful and scalable. However, there are a number of issues. The main one deals with data storage and access. On the plus side, the blob could provide more attractive storage for binary large objects than what IT management has without the cloud or without Windows Azure.
But most data used in apps is relational. The table storage type isn't able to handle all relational data. Instead, it can only handle simple-structured or semi-structured data. Although table has distribution built into it through the Partition Key concept, it's really not a substitute for a relational database.
A relational database can be hosted by Windows. In addition to the above three storage types, Microsoft is also making SQL Server available in Windows Azure with what it calls the SQL Azure Database. Although SQL Azure Database uses SQL Server underneath, it provides a services interface to the clients in the Windows Azure environment. And although Microsoft will eventually make the entire set of SQL Server features available in the cloud under SQL Azure, right now it's providing only a subset of these features.
Storage Still the Bottleneck
Although Windows Azure provides many more scalable storage options than your typical non-cloud application, storage is still the scalability bottleneck. That's because the SQL Azure Database is built on top of SQL Server and will suffer from the same scalability issues as SQL Server. Moreover, table storage isn't really a substitute for a relational database.
Therefore, as you scale out your application in Windows Azure, your storage will still be the bottleneck, and you need to plan for it. So, we return to the original question: What are the scalability bottlenecks in cloud computing, and what can we do to alleviate them?
You still need something else to augment the scalability limitations of the Azure storage options. That something else is an in-memory distributed cache that's extremely scalable because it's much simpler than either a table storage type or SQL Azure. Because of its in-memory storage, it can scale very nicely and provide much faster access time.
As shown in Figure 3, IT pros need to consider distributed caching in Windows Azure as another storage option, but one that's transient and not persistent. It doesn't replace the other storage services that Windows Azure provides, including SQL Azure; it augments them. Web and worker roles connect to the cache and check the cache first before they go to any of Windows Azure's storage options.
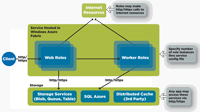
[Click on image for larger view.] |
| Figure 3. Distributed caching architecture in Windows Azure. |
Enhancing Scalability
Most cloud applications are mission-critical because so many people use them. User numbers can range from a few thousand to hundreds of thousands. Therefore, distributed caching plays a major role in the cloud-computing environment. Thankfully, there are a number of products available. Some are free. Others are commercial. Keep in mind that not all distributed caches are created equal. It's crucial that you closely investigate a distributed cache's characteristics, features and caching topologies.
Distributed Caching Features
Here are some important aspects of distributed caching for cloud-computing environments:
- Performance and Scalability: First and foremost, a distributed cache must have top-notch performance. Additionally, it should scale seamlessly when your application needs to scale. Scalability here means that, as you add more cache servers to your environment, your transactions-per-second capacity should grow linearly.
- Reliability: A distributed cache should possess high reliability. Reliability here means no loss of data even when a cache server goes down. Even though, in many cases, you also have the same data in the database, it's still very costly to rebuild the cache again at runtime. In many other cases, your cache data isn't stored anywhere else because of its transient nature -- for example, ASP.NET Session State data -- and you absolutely can't afford to lose any of this data from the cache.
- Availability: The next major characteristic is high availability, which means the cache is a storage area for your application and therefore should be available all the time. If you need to add or remove a cache server from your cluster, you should be able to do so without stopping a thing. This is particularly important in cloud computing, where you regularly scale your configuration up or down in order to handle different load levels. You should be able to do so without any interruptions or stoppages.
- Expirations: Expiration allows the cache to automatically remove a cached item after a certain time. Expirations can be either on absolute time or idle time. Absolute-time expiration removes an item at a given date-time and ensures that a cached item won't become stale because data in the database might change by that time. Idle-time expiration removes an item if nobody touches it for a given time period, and allows you to automatically clean up unused items.
- Evictions: A distributed cache stores data in memory and therefore must handle situations when the cache is full and has consumed all the memory available to it. When a cache is full, some items have to be removed in order to make room for new items. This is called eviction. A cache automatically evicts items based on an eviction policy. Three common examples are Least Frequently Used, Least Recently Used and Priority. Some caches also allow you to specify that no item should be evicted and that, instead, the cache should stop accepting new items until some items automatically expire.
- Data Relationship Management: Most data today is relational, but the cache isn't an in-memory relational database. Instead, it's a key-based storage mechanism that stores an object for each key. But this doesn't address the relationships among different data elements. For example, a customer may have one or more Order objects associated with it. If you remove the customer from the cache, you might also want to remove all of its related Order objects. A good cache should support this feature. In fact, ASP.NET Cache has introduced CacheDependency just to handle issues like this.
- Database Synchronization: Databases are usually shared among multiple applications. One application may be using a distributed cache, while others may not. If this is the case, you'll have times when the data in the database is updated by another application, resulting in a cache with stale data. For these situations, a good cache provides database synchronization. In this feature, a cache either removes or reloads a cached item when its corresponding data is updated in the database. The cache then finds out about this situation, either through events fired from the database or through polling. Both methods are fine as long as the synchronization is occurring at row-level and the polling interval is configurable.
- Read- and Write-Through: There are two ways you can use a cache. One is for your application to keep the cache "on a side." With this method, your cache directly reads and writes the data to the database. Whatever you read from the database, you put in the cache, and whenever you update anything in the database, you also update it in the cache. Another way is for your application to rely on the cache to do all or most of the reading and writing to the database. With this option, your application only deals with the cache. In such situations, you would need to provide Read-through and Write-through handlers. This is your custom code that's registered with the cache and is called by the cache whenever it needs to read or write data to your database.
- Tagging: Tagging allows you to arbitrarily group cached items into multiple categories by specifying those tags. This is a powerful way for you to keep track of various cached items and manage them as a group later.
- Object Query Language (OQL): Normally, a cache is key-value storage where the value is an object. This means that if you want to find an object, you must know its key. If your cache allows you to search for objects based on their attributes, this makes the cache very powerful. With OQL, you can start to use the cache very much like a database by using SQL-like queries. For .NET applications, Language-Integrated Query (LINQ) is now becoming a standard object-querying language, and a good cache should therefore support LINQ.
- Events: Event propagation is a good feature to have for distributed applications, high-performance computing applications or multiple applications sharing data through a cache. This feature asks the cache to fire off events when certain things occur in the cache. Then, your applications can capture these events and take appropriate actions.
Caching Topologies
An effective cache should have the following topologies: replicated, partitioned, a hybrid of replicated and partitioned, and client or local cache. Different topologies for different uses make a cache extremely flexible. A replicated topology replicates the cache many times, depending on how many times you need to replicate it. It's intended for situations where you have read-intensive cache usage but not a lot of updates.
Partitioned cache is a highly scalable topology for update-intensive or transactional data that needs to be cached. It's excellent for environments where you need to do updates at least as many times -- or almost as many times -- as you're doing reads. In some cases, you might do updates even more often than that. This topology partitions the cache. As you add more cache servers, the cache is further partitioned in such a way that almost one Nth -- N meaning the number of nodes -- of the cache is stored on each cache server. Partitioned cache also has the option of backing up each partition onto a different cache server to reliability.
Client cache is a highly useful topology that fits on the application server, close to the application. It's usually a small subset of the actual large distributed cache, and that subset is based on what that application at that moment has been requesting. Whatever that application requests, a copy of it is kept in the client cache. The next time that application wants the same data, it automatically finds it in the client cache. Having a client cache gives you additional performance and a scalability boost.
These are the characteristics, features and caching topologies that make up a robust and efficient commercial-grade distributed cache. You're taking a risk if you choose free or low-cost products that lack these vital features.
Free distributed caches, especially, don't have the strength for a high-end environment because they lack scalability and high availability. Also, they don't have most of the key features forming the foundation for intelligently caching data and always keeping the cache fresh. A cache has to have the right intelligence to make sure it's always correct.
So, the question becomes: Are you willing to compromise and improvise with lower-quality distributed caching and, as a consequence, face a high probability of costly downtime and bottlenecks?
Moving into the Cloud
Prudent IT managers will opt for high-quality distributed caching for the Windows Azure environment. One thing to understand is that for an application to run in the cloud, like Windows Azure, the development team has to architect its applications to make them compatible with Windows Azure. Microsoft has come out with a highly sophisticated framework, and applications need to comply with it. That's a considerable development effort.
Distributed caching needs to be plugged in when you're in the process of re-architecting for the cloud or developing a new application for the cloud, as shown in Figure 4. If your developers aren't fully aware of important distributed caching attributes, it falls on you as an IT manager to explain how important they are to your successful IT operations.
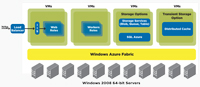
[Click on image for larger view.] |
| Figure 4. Integrating distributed caching into your architecture is important. |
Right now, there's no distributed caching API standard, and each caching solution, free or commercial, has its own API. Microsoft is working on a standard for .NET, which is its cache-extensibility API, and the standard is likely to be a part of .NET 4.0. Once introduced, every cloud developer should program against this Microsoft standard. That will allow you to plug in a distributed caching solution of you choice, free or commercial, without any code change. This is because most of the caching solutions will start supporting this Microsoft standard on the .NET platform.
Until that comes, the only option is to select a caching solution; make sure that caching solution is available inside the Azure environment; and then develop against it. Also, when your developers deploy it, that caching solution should be available inside Azure for the application to use.
Lastly, Windows Azure hasn't been fully released as of this writing. It's scheduled for release near the end of this year. Until then, it's still in a community-release stage. Developers are creating applications against it and generally checking it out. However, it'll be taken a lot more seriously once it's released and shows more stability.