SSIS's New Look Lookup
Let's look at the much-improved Lookup transformation feature in version 2008.
- By Eric Johnson
- 10/05/2009
SSIS is a pretty useful tool for designing ETL processes, but one of the transformations I was disappointed with in 2005 was the lookup. It was a little better than the lookup functionality in DTS, but not by much. Well, Microsoft must have read my mind because SQL Server 2008 has a new shiny Lookup transformation that is, in my opinion, much improved.
In 2005, the lookup had cache options, but they were really heavy handed. And you could deal with a lookup not finding a match by using the error output, but then how would you know the difference between a non-match and a real error? Let's start with the cache. There are now three cache options and two choices for your cache source.
Full Cache -- This will load the entire reference dataset into memory before the first lookup is performed. This can be very efficient for small tables, but think what would happen if your lookup table was a few GB in size ... that's a lot to load into cache.
Partial Cache -- This is probably what most people think of when they conceptualize lookup cache in their head. At first, the cache is empty and each time a row matches or doesn't match for that matter, the row, or the fact that the lookup didn't find a row, is cached. Subsequent rows with the same lookup fields will find their data, or lack thereof, in cache.
No Cache -- The lookup will generate the reference dataset each time the transformation runs.
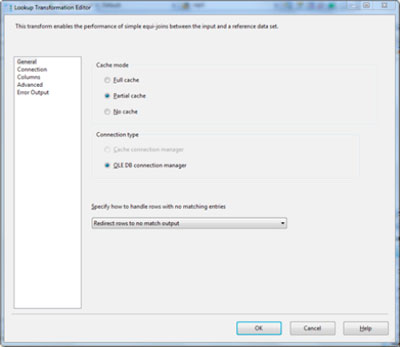 |
| Figure 1. SSIS's Lookup cache options via this Lookup Transformation Editor dialog. |
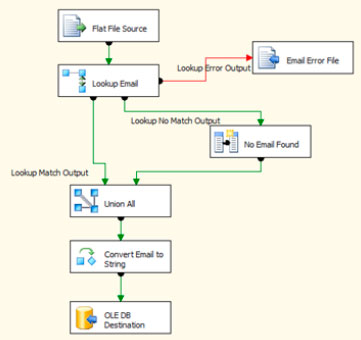 |
| Figure 2. A new way of seeing things. |
As for data sources for your cache, you can still go to the database, but now you can also set up a custom cache connection. This gives you the ability to build your cache in a separate step and then reference it with your lookup. This is a little involved so I won't go into detail here, but you might see it covered here in the future. Furthermore, if you use the partial cache, you can manage your cache size on the Advanced page of the Lookup's properties.
So I like the changes to caching, but I like the output options even more. You can now specify that rows with no match be redirected to their own output or be ignored all together. This now gives you three outputs to work with: one for a match, one for no match, and another for errors.
I put together a small sample package, shown in Fig. 2; you can see that I am using all three outputs. In this case, when an e-mail address is not found in the lookup, I use a derived column to put "NA" into the e-mail address column before I load. We then take this data and union it with the rows for which the lookup found a match and do an insert into the destination table.
In the end, this new lookup is much cleaner and easier to use than its 2005 predecessor. Plus the addition of the Cache Connection Manager is a big win. More on that, coming soon.
About the Author
Eric Johnson, SQL Server MVP, is the owner of Consortio Services in Colorado Springs providing IT systems management and technology
consulting. He is also the President of the Colorado Springs SQL Server
User Group. He can be contacted at www.consortioservices.com.