In-Depth
Building Massively Scalable Grids
When done right, Enterprise Data Grids offer utility-style computing and easy expansion.
An Enterprise Data Grid is a new form of IT infrastructure that gives high-transaction applications improved scalability and reduces the stress they impose on the database. For .NET and Windows platforms, these applications could be ASP.NET applications or service-oriented architecture (SOA) applications developed as Windows Communication Foundation (WCF) services and hosted in IIS or TCP in a multiserver environment. These applications can be developed in C#, VB.NET or any of the leading programming languages. Similarly, applications developed in Java, PHP or other programming languages fall into the same category.
Grid Computing has recently become popular for applications that need massively parallel computation, a need addressed by Microsoft HPC Server 2008. A Compute Grid is a collection of servers that can easily scale to hundreds or even thousands of servers, allowing that much more parallel computing to be distributed in the Compute Grid. A Compute Grid seamlessly expands computation power through inexpensive hardware.
Similarly, a Data Grid is a collection of inexpensive servers that may not have a lot of CPU power but have a lot of memory -- and memory these days is cheap. Usually, these are 64-bit servers, so each server can have many gigabytes of memory available. Just like a Compute Grid, a Data Grid scales seamlessly to tens or hundreds of servers and can pool the servers' memory as one large logical storage unit, scaling both the memory-storage capacity and the read-write transaction capacity of the Data Grid.
Today, more and more applications must scale. ASP.NET, for instance, lets applications handle hundreds of thousands and sometimes millions of simultaneous users. A Data Grid provides an in-memory scalable data store for temporary or transient data that most applications need or have.
This data is unlike that in a traditional database, which stores it permanently. This data is needed for as short a time as a few minutes to as long as days and weeks. But it's not something that needs to be kept permanently, and it needs to go away after it has served its purpose.
An Enterprise Data Grid can be thought of as a collection of Windows servers with an in-memory data store that can scale. This cluster of Windows servers lets applications store transient data in memory. The total memory size grows as you add more servers to the Data Grid. Also, the Data Grid's total transaction capacity grows as you add more servers to the Grid.
If you have tens or even hundreds of application servers all going to a few common database servers, your goal should be to reduce traffic to those database servers. You do that by going more and more frequently to the Enterprise Data Grid. This way, your database servers perform faster because they don't have as much load from repetitive read requests. As a result, they update requests much faster. These updates must be done to the database because it's the master data source.
The database server can't scale out beyond a couple of clustered servers to grow transaction capacity. However, an Enterprise Data Grid can scale out seamlessly and endlessly, providing virtual linear scalability.
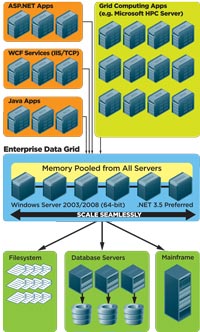
[Click on image for larger view.] |
| Figure 1. An Enterprise Data Grid being shared by multiple applications. |
Data stored in the Enterprise Data Grid is application data; session data, in the case of Web or SOA applications; or any other temporary or transient data not fit for permanently storing in the database. Application data deals with customers, orders, products and inventories, for example. Session data, as the name implies, is data kept only for the duration of a user session of a SOA session. The Data Grid is becoming an important infrastructure that Web applications tap into to improve both applications and user session data.
Applications data is data the applications would otherwise be reading and writing to the database. That data is put in the Enterprise Data Grid as soon as applications read it the first time from the database. Or, the apps ask the Enterprise Data Grid to read it for them from the database. Either way, it's put in the Enterprise Data Grid.
From that point on, multiple users can read that same data over and over again and improve their performance and scalability because the Data Grid scales very nicely. As you increase the number of application servers, you can keep adding a proportionate number of servers to the Enterprise Data Grid, and capacity keeps growing.
As for session data, all Web and SOA applications need to have it. It has to be stored somewhere and needs to be accessible from all Web farm servers. The Enterprise Data Grid provides a common data store where all Web servers can go and fetch the sessions. The Web servers scale linearly and don't have to use the sticky session bit in the load balancer off the Web farm.
Key Features
From a data-storage perspective, it's important to have a group of features that ensure data is always fresh. There's a master copy of the application data existing in one or more databases. You must ensure that your copy never becomes inconsistent from the master copy because the applications may not be able to tolerate any inconsistencies.
However, keep in mind that different types of data have varying levels of sensitivity. In some cases, it's OK to be inconsistent some of the time. But for other data, it's never OK to be inconsistent. Either way, the Enterprise Data Grid must maintain fresh data.
Expirations, database dependencies and cache dependency are valuable features that help keep data fresh and ensure that data stored in the Data Grid is always correct.
Expiring data is the most important feature. When the application adds data to the Data Grid, it needs to be able to tell the Data Grid to expire it after a predetermined time. Application developers determine that specific time based on what the data element is. For example, product pricing information doesn't change frequently, but product inventory does. Customer address information may not change a lot, but customer order information probably changes all the time.
Along the same lines, some transient data may not even have a master data source -- for example, session data. You want that data to expire on an idle or a sliding-time manner instead of on a fixed, absolute time. Here the purpose is not to keep it fresh, because there is no master copy; rather, you want to clean it up and not let it sit in the Data Grid and take up space. Once the application is done and is no longer being accessed, you can let the data expire.
For example, a user's session data could expire if that session isn't accessed for 20 minutes, which is standard in Web applications. The application should be able to specify both absolute and sliding-time expiration. Absolute expiration is for data that's in a master database; sliding-time expiration is for data that may not have a master.
A lot of the time, data kept in the Data Grid is also in a master database. But some other third-party applications may directly update it in the master database without updating it in the Data Grid. If your application updates the database, you should probably design it to update the Data Grid as well, so both have the same fresh copies.
Third-party apps may also need tweaking to work with a Data Grid. This is why Microsoft introduced the concept of SQL cache dependency, which some commercial .NET-based Enterprise Data Grid vendors have expanded. SQL cache dependency allows applications to specify -- while adding data to the Data Grid -- that the added data element is dependent on a particular row in a particular table of the database. With SQL cache dependency, you're telling the database server to send a .NET event notification to the Data Grid whenever that specific row is updated, and allowing the Data Grid to keep track of the situations where that data changes in the database -- and when it happens. At minimum, it involves removing the old copy from the Data Grid so the next time your application wants it, it won't find the old copy in the Data Grid, and the application will have to go to the database.
The same is true for absolute-time expiration. When you let the data expire through absolute-time expiration, it's because you fear that data in the database has changed. At that point, you can use a read-through to reload that same item from the database instead of just expiring data.
SQL cache dependency lets you synchronize your Enterprise Data Grid against your SQL server database. The .NET events the database fires happen because SQL 2005 or 2008 now has built into it the .NET Common Language Runtime (CLR), which essentially means there's a .NET environment within the database. In fact, Oracle 9i R2 or later versions on the Windows platform also have .NET CLR built into them and can fire the same events. This allows you to synchronize against the database based on .NET events.
If your database is not one of these two, then the Enterprise Data Grid should still help you achieve the same goal, but by using polling instead. The Data Grid should have a configurable polling interval after which the Enterprise Data Grid polls for specific data in the database. Here you're looking for whether that data has changed or not. If that data has changed, it does the same thing again: either removing that corresponding item from the Data Grid or reloading a new copy from the database. Polling should also be able to do row-level mapping instead of table-level mapping.
Those features, as well as Microsoft's ASP.NET's cache-dependency feature, are important for keeping data fresh. Through cache dependency you can manage relationships between different data elements. Most data from the database is relational, meaning different data elements are related to each other. If one data element changes, it affects another data element.
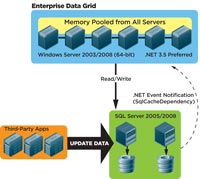
[Click on image for larger view.] |
| Figure 2. An Enterprise Data Grid synchronizes with SQL Server 2005/2008. |
For example, if you were to delete an Order in a database, it would automatically delete all the Order Items related to that Order. That's because the Order Items in the database have no meaning unless they are within an Order. Similarly, an Order must belong to a Customer -- it has no meaning without a Customer.
Therefore, when you have these different data elements in the Enterprise Data Grid, it makes sense for them to relate to one another. If a particular Order object is removed or updated, corresponding Order Items are automatically removed.
Essentially, if one item in the Data Grid depends on another item, if that other item is ever updated or removed, the depending item is removed, as well. This frees up the application from having to keep track of all the different data items related to each other that have to be removed from the Data Grid to keep data fresh.
Read-through is another key feature of the Enterprise Data Grid. A lot of data kept in the Grid is information the applications should directly get from the Data Grid instead of always loading it from the database. However, you can't do this for all data, because in some cases it's better to read it from the database.
Take for example a product catalog with pricing information or inventory. You can have one application load this data into the Grid where it's kept, and then have all other applications read it from the Data Grid. In this instance, the Data Grid should have the ability to automatically keep this data fresh. Combining read-through with SQL cache dependency or expirations allows you to reload a fresh copy from the database when needed.
Read-through involves you writing handlers that get registered with the Data Grid and the handler code actually running on the Data Grid servers. It enables the Data Grid to call your code to go and read that data element from the database.
Similarly, there is write-through. When applications update the data in the Data Grid, the applications want the Data Grid to update corresponding data in the database. The Data Grid calls your write-through handler, which is also your custom code that's registered and runs on the Data Grid. Your code then goes and updates the database.
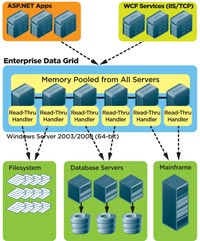
[Click on image for larger view.] |
| Figure 3. Read-through handlers running on Data Grid servers. |
In the case of updates, it's a good idea not to ask applications to wait until the database is updated, because that slows them down. If the data is extremely sensitive, applications don't want to go away and assume that the Data Grid has updated the data in the database.
Once the Data Grid update is done, the database update part should be queued up -- and the application doesn't need to wait around for it to be completed. The application can then go do other things while the Data Grid is updating the database. This feature is called write-behind. With write-through, applications wait; with write-behind, applications don't wait, and the Data Grid takes care of the database.
With write-behind, the Enterprise Data Grid should keep multiple copies of that queue, so if any one server in the Data Grid goes down you don't lose the information about what was supposed to be updated in the database. Otherwise, it could be disastrous.
Event notification is another important Data Grid feature because some applications need to collaborate asynchronously. When an application puts something in the Data Grid, it can fire an event so other applications can pick up that data element and use it appropriately. This is especially vital in distributed applications.
Creating the Data Grid
When you build an Enterprise Data Grid, you basically put two or more servers in a cluster, usually vendor-specific machines tied through Windows clustering. But it's a cluster created by the Data Grid product. In this case, all the servers know each other; they're an integral part of a Data Grid; and information can be shared among them. Hence, they provide one logical data store that spans multiple servers.
From an applications perspective, you may have 20 servers in the Data Grid and the memory of all those servers is pooled together to create one large logical memory. Servers in the Data Grid take care of distributing data to different servers, replicating them in some cases to ensure there's no loss of data in case any one server in the Data Grid goes down. But, essentially, they build a cluster to know about each other.
Once the cluster is built, there are some clustering-specific features you must have. The most prevalent is maintaining 100 percent uptime. A Data Grid is shared by many mission-critical applications, so it's foolhardy not to have 100 percent uptime.
The second feature is the ability to make changes, which is associated with 100 percent uptime capability. You must be able to dynamically make changes to the Data Grid at run time without stopping anything. You should be able to add a new server for more capacity, or drop a server for reduced capacity or maintenance on some servers while the Grid is running.
The Data Grid needs to grow in two ways: in read-write transaction/sec capacity and storage capacity. By adding more servers to the Data Grid, you're putting in more
processing power, more network cards to accept more client connections, and increasing the total number of reads and writes that all clients combined can do at once. This is something your database can't easily scale for, but a Data Grid can seamlessly do.
Usually, it's a good idea to use a 64-bit hardware and software platform. With 64-bit you can easily get more than 4GB memory in each box with 16GB to 32GB being the norm.
Data Grids support a partitioning topology. The entire data set you're storing in the Data Grid is automatically partitioned by the Data Grid. Every partition is stored on a different server, so the number of partitions equals the number of servers. As you add a new server, it creates a new partition and the new partition includes more storage space. That allows you to scale overall storage capacity.
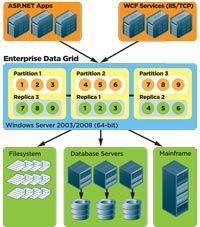
[Click on image for larger view.] |
| Figure 4. Partitioning with replication topology in Data Grid. |
Another data storage topology is a hybrid of partitioning and replication. There are different types of replication possible, but the most suitable for an Enterprise Data Grid is replication with partitioning. This means every partition stored on a server in a Data Grid has a replica or a backup on a different server in the Data Grid. You can have more than one backup, though this is rarely necessary.
So, if your Data Grid has three servers with one partition each (partitions 1, 2 and 3), each server keeps one partition and one backup of another server's partition. This way, if any one server goes down, no data is lost, although there's a brief period of time when the Data Grid is vulnerable because it's redistributing the partitions to adjust to the new server count and creating a fresh backup of one of the partitions. Fortunately this vulnerability period is brief, usually not more than a few minutes to perhaps an hour if you have a really large Data Grid. During this vulnerability period, if a second server also goes down, you might lose some data, but the probability of two servers crashing so close to each other is low.
In addition to increasing storage capacity, partitioning also expands transaction capacity. The more servers you add, the more reads and writes per second capacity you have in the Data Grid. Let's say you had a Data Grid made up of three 16GB servers, and it allowed about 90,000 reads per second and about 75,000 writes per second. By adding a fourth 16GB server, you add more storage capacity and it bumps it up to 120,000 reads and about 100,000 writes per second.
When you have a 100 percent uptime environment, you can add a new server to the Data Grid at run time. It should automatically add a fourth partition, copy some of the data from the existing three partitions, create a replica for the fourth partition, and move the replica of one of the existing partitions to the fourth partition.
In addition to partitioning, the Data Grid should have a client-cache topology. This topology automatically allows all applications to keep a subset of the data that's in the Data Grid within the client application or application server. This subset of data is based on the usage pattern of each client application and usually keeps the most recently used data in the client cache.
Client cache also provides a further boost to performance and scalability. Keep in mind that these client caches have to be synchronized with the Data Grid. They can't be kept as isolated local caches on the client machines, or you'll end up with data integrity issues. Whatever is in these client caches is also in the Data Grid. If client cache changes are made in the Data Grid, it's the Data Grid's responsibility to update client caches or to notify them so they can update themselves almost immediately.
Finally, just as you've grown used to having monitoring tools for your database servers, your Data Grid should also be equipped with powerful monitoring tools.
Applications
Applications well-suited for exploiting an Enterprise Data Grid include ASP.NET, PHP and Java JSP programs, as well as Web services developed in .NET or another technology. These are all highly scalable application architectures.
Distributed computing is another type of application. Distributed computing is a vague term, but large corporations with high-traffic Web applications best define this term. They have back-end server processes processing data in batch mode overnight. These are multiple applications, with multiple processes that need to collaborate. One application does one thing, and then its output is used by the application to do something else. It's almost like a workflow, but it's done in an automated fashion.
Take, for example, the distributed applications used in stock-trading companies. They perform an inordinate number of real-time interactions with their users and also on the back-end with the stock prices. There are multiple applications on different servers that in real-time need to talk to each other and collaborate.
If these environments had a common Enterprise Data Grid, it would make life a lot easier by simply sharing data between them. Most applications represent data in terms of objects, so they can store these objects in the Enterprise Data Grid easily and talk to each other.
Last, but not least, high-performance computing apps need an Enterprise Data Grid. These applications can have thousands of servers processing large amounts of massively parallel computations. They need considerable amounts of data to perform computations and collaborations, and need to do things in a short burst and simultaneously use a lot of servers. They need a scalable data store, and the Enterprise Data Grid provides that data store.