In-Depth
Backup vs. Replication and Why You Need Both
Some see them as competing technologies. The reality is that they go together like peanut butter and jelly.
Disaster recovery (DR) is one of the most critical insurance policies in which a business can invest. A high-quality disaster recovery strategy can be the difference between a minor speed bump and a business-ending tragedy. As such, it's important for business leaders to understand the components that make up a well-rounded DR plan and know how to leverage each to meet their business requirements.
Definitions
Before reviewing the technical methods for protecting a business from disaster, the foundational business measurements must be understood. In many businesses, a standard set of measurements is defined that makes certain promises to the rest of the business with regard to the availability of services. Although there are others, there are three types of measurements that commonly appear in a DR conversation.
Service-Level Agreements: Frequently abbreviated as SLA, a service-level agreement is a contract of sorts that establishes the scope and quality of a service that will be provided. Sometimes this sort of agreement is negotiated between a third party and the business, like a public cloud provider, for example. It can also define goals for services offered to a customer, like a help desk or call center. In the context of DR and this article, SLAs are also internal—and often informal -- contracts between IT (or other departments) and the rest of the business. These agreements define things like:
- To what level business data will be protected from infrastructure failure
- How long business data will be retained in archives
- How "available" business services will be (the amount of downtime that will be tolerated)
- The granularity with which lost data can be recovered
SLAs are very important in the context of DR, because they define the targets for the entire DR plan. The sole purpose of crafting a sound DR strategy is to ensure that SLAs are met. If SLAs are fairly aggressive, a robust, multi-faceted DR strategy might be required in order to meet the demands of the business. But if SLAs are fairly lax, perhaps a simple nightly backup will suffice. This is why SLAs are so important to define.
Recovery Point Objective: Recovery point objective (RPO) and the next metric, recovery time objective (RTO), could actually be part of an SLA. But they're important to call out on their own because these two measurements are two of the most important in determining which technical measures to take to meet the requirements. RPO establishes the amount of data a company is willing to lose in the event of a disaster. This is a delicate balance, but easily calculated with access to the right numbers. Simply, it comes down to finding the break-even between the cost of lost data and the expense to ensure against losing data. When it costs more to bolster the data protection mechanism than it costs to just lose the data, you've found the right point. Of course, this is never an exact science because it's effectively insurance and failures aren't predictable; theoretically, a business could have no failures and have "wasted" money on DR. But if a business finds itself on the other end of the spectrum and has many disasters that were all gracefully recovered from, the investment in the DR mechanisms more than paid for itself.
RPO is measured in time. For example, we're willing to lose 15 minutes worth of data. This means that all data that is older than 15 minutes must be adequately protected and restorable within the RTO in the event that the primary copy of the data or the services becomes unavailable.
Recovery Time Objective: RTO balances the DR equation and specifies the amount of time after the failure that will be tolerated before the service or data is restored. This metric is measured in units of time just like RPO, so an RTO of 15 minutes for a specific service indicates that after a failure, the data or service must be available again within 15 minutes at the RPO (maximum amount of data loss) expected.
Similar to calculating a reasonable RPO, calculating a reasonable RTO just requires the correct inputs. The break-even between the cost of lost staff productivity or customers served and the cost of the DR mechanism is the sweet spot here. Combined, RPO and RTO will make up the total amount of loss in a DR scenario. Sometimes, they'll end up being symmetrical, like the example I've been using: an RPO and RTO of 15 minutes. In some business cases, like a business that processes a high volume of transactions every minute, both RPO and RTO should probably be high. In other cases, like a video production company, a short RPO but a longer RTO could possibly be tolerated.
With an understanding of the business targets and the way they're measured, it's possible to logically evaluate the technical methods for achieving these objectives. Now I'll explore the difference between backup and replication and see how they relate to RPO and RTO goals. While there are technically many more components of the full DR strategy, these are two of the most widely leveraged tools in the DR mechanic's tool chest.
Start with Backup
Backups are the cornerstone of any DR solution, and have been around since the days of punch cards. For as long as you've been storing data, you've been wise enough to keep backup copies of that data. Today, backups can be considered the first or second line of defense against data loss, depending on how you look at them. From an infrastructure perspective, backups are really the second line of defense; the first is infrastructure resiliency and fault tolerance. Should that fail, restoring backups could happen next.
But failure isn't the only cause for data loss; you must also consider possibilities such as user error. In the case that a user manually but unintentionally deletes a file that they really wanted to keep, backups are the first line of defense in recovering that file.
One of the key points I want to make in this article is that backups and replication are complementary, accomplish different goals, and should be used together; it's not an "either/or" discussion where just one of them will solve the problem. As I mentioned, the only purpose for any technological approach is to meet the defined SLAs of the business. With that in mind, the question at hand is: How do backups help achieve RPO/RTO goals? And how are they configurable to meet different levels of RPTOs (an abbreviation used to discuss both goals at once)?
For the purposes of this article, a backup will be defined this way: "Backup is the activity of copying files or databases, so that their additional copies may be restored in case of a data loss accident." Backups take more of a "long term" approach to protecting the datacenter.
Backups store data in a holding area to meet the sort of SLA that says, "We will be able to recover data from a specified data set from any point within the last 30 days with a 15-minute RPO." This SLA states that unless the data was altered 10 minutes ago or 31 days ago and is outside the scope of the RPO, it will be recoverable.
Archival: A Subset of Backups
It's worth mentioning that backup data is treated in two different ways. Primarily, backup data is available to meet production workload RPTO requirements and will be kept available as such. But many organizations also have regulatory mandates to retain data for a certain period of time, and some choose to retain data for a long time, even though they aren't required to, just in case they would ever need it.
This data that could be years old is commonly referred to as "archive" data, and might be treated as another tier outside of the production backup system. While archived data might take longer to retrieve and restore, it is still a part of meeting SLAs and a part of the overall backup strategy.
Complement with Replication
Replication is the act of synchronizing data between a primary site and a secondary/DR site for the purpose of resiliency. Oftentimes, replication is viewed as superior to (or a preferable alternative to) backups. This is not the case, however. While replication can help shorten RPTO targets, it becomes prohibitively expensive to have long retention periods where a recovery can take place within the RPTO target time frame and backups are the key for retention.
The trick, therefore, to creating a successful DR strategy, assuming RPTO goals are somewhat aggressive, is to leverage both backup and replication (among other tools), rather than one or the other. In fact, for comprehensive protection, they should even interact with each other. Take Figure 1 as an example. This is one way that backup and replication tools could be used together to create a DR strategy that covers more of the exposure to risk.
In the example, production data is being backed up on a regular basis to a local backup repository. These backups are restorable within a short period of time, and data is kept in this local repository. Any file needed is recoverable with no dramatic action taken. The primary site is also protected by replication such that in the event of a site-level disaster, the workloads could be failed over to the DR site and critical services could be back online in roughly 15 minutes. Although a failover is more dramatic, it has a low RPTO and can restore services in short order.
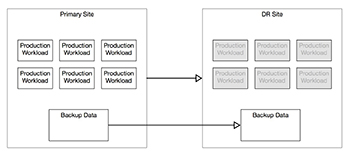 [Click on image for larger view.] Figure 1. Backup and replication working in tandem provides the best solution in most cases.
[Click on image for larger view.] Figure 1. Backup and replication working in tandem provides the best solution in most cases.
Working together is where backup and replication really shine. Near the bottom of Figure 1, backup data is being replicated to the DR site. This means that not only is backup data with long retention available for restores, but it's highly available because it's replicated to the DR site. Imagine that a tornado wiped out the primary site, but there were no backups and only replication was being used for high availability. In this sad scenario, the business would be up and running with the data that was available at failover, but old data would not be available for restore as it was destroyed in the disaster. This illustrates why the use of both technologies together is commonly the best strategy.
About the Author
vExpert James Green has roughly a decade of experience as an IT administrator, architect and consultant in a variety of organizations. He's highly certified, and continues to purse professional certifications to increase his breadth and depth of knowledge. He has always been passionate about writing and speaking, and discussing the marriage of cutting-edge technology and business is one of his favorite activities. He works for ActualTech Media, www.actualtech.io.